将卷积神经网络的识别过程可视化有助于我们理解卷积神经网络的工作过程。我们基于Zeiler的论文在ImageNet上面训练的CNN来讲解,大神的视频可以看链接:视频链接。我们将看到每一层输入的是什么,以及它们是怎么检测越来越复杂的图形的。
Layer1

上图表示了导致第一层网络激活的元素,包括各种线条以及光斑。这张图中每个网格都代表着能让第一层网络中的神经元激活的元素,换句话讲,这些是第一层网络可以识别的元素。左上角的图片显示识别一条-45度的斜线,中上角网格显示的是识别45度斜线。
我们再来看能够导致神经元激活的更多的图片例子。以下的图像都会激活识别-45度的神经元,可以注意到以下的不同图片有不同的斜率,不同颜色,不同特征。

所以CNN的第一层只是选取非常简单的形状或特征比如说线条和光斑。
Layer2

上图表示CNN的第二层的可是化,需要注意到的是这一层网络开始识别比较复杂的特征比如说圆圈或者条纹。左边的网格表示这一层的神经元基于右侧网格中的相应图像如何被激活
我们可以注意到,CNN的第二层开始识别圆圈,条纹和矩形。
以上的识别是CNN自动完成的,而不是我们编程让CNN去识别某一个特征的。
Layer3
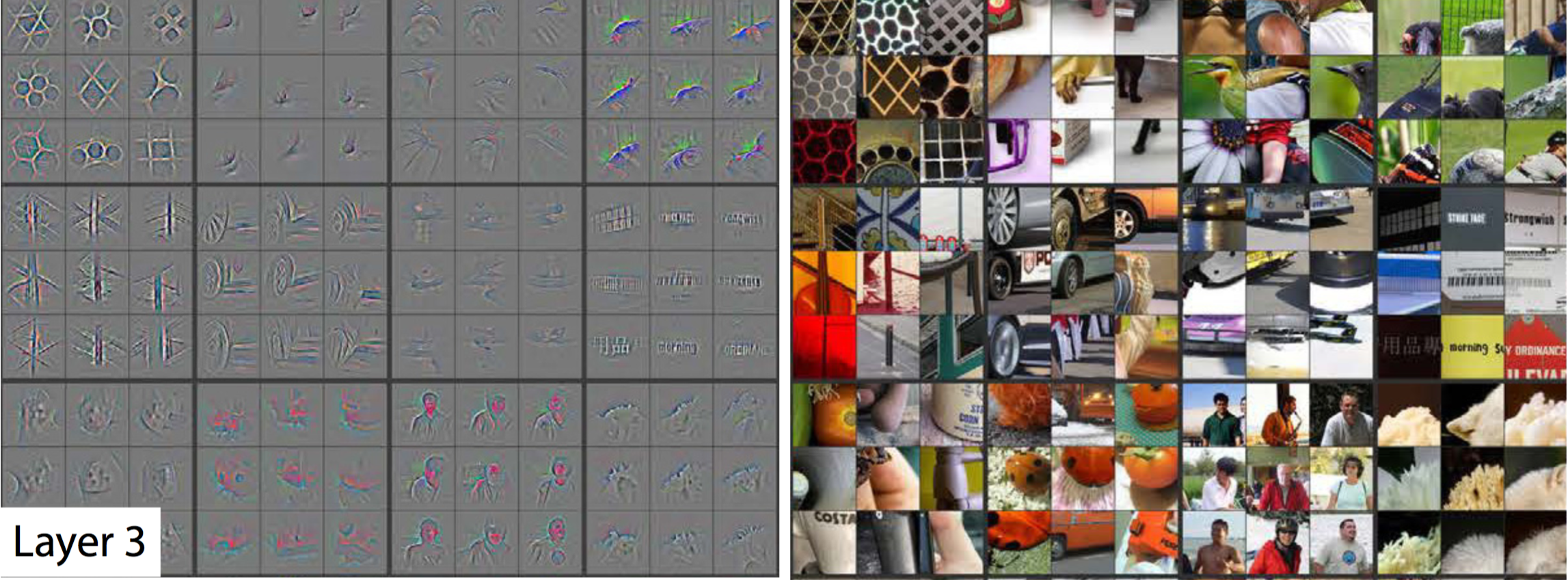
上图是CNN第三层的可视化结果,左侧灰色的网格表示当输入右侧相关图像时第三层神经网络所能看到的信息。第三层选取第二层输出组合成复杂特征。包含网格,轮子,脸等等
Layer5

我们跳过了第四层,这是因为第四层也是重复第三层的工作,选取上一层的输出作为组合。我们直接跳到第五层也就是输出层。这一步选取更高层级的特征,用于分类,识别出狗,鸟,自行车等物品
在TensorFlow中使用CNN
我们用一个代码片段示意如何在TensorFlow中使用CNN。
TensorFlow提供了tf.nn.conv2d() 和tf.nn.bias_add()两个函数来建立卷积神经网络,实例代码如下:
# Output depth
k_output = 64
# Image Properties
image_width = 10
image_height = 10
color_channels = 3
# Convolution filter
filter_size_width = 5
filter_size_height = 5
# Input/Image
input = tf.placeholder(
tf.float32,
shape=[None, image_height, image_width, color_channels])
# Weight and bias
weight = tf.Variable(tf.truncated_normal(
[filter_size_height, filter_size_width, color_channels, k_output]))
bias = tf.Variable(tf.zeros(k_output))
# Apply Convolution
conv_layer = tf.nn.conv2d(input, weight, strides=[1, 2, 2, 1], padding='SAME')
# Add bias
conv_layer = tf.nn.bias_add(conv_layer, bias)
# Apply activation function
conv_layer = tf.nn.relu(conv_layer)
以上的代码使用tf.nn.conv2d来计算卷积,使用weight来作为滤波器,[1,2,2,1]作为步幅。TensorFlow对每个输入维度使用一个步幅,[batch, input_height, input_width, input_channels]。我们通常设置batch和input_channels的步幅为1.
我们在设置batch和input_channels为1时应该关注修改input_height和input_width。这两个值的步幅会在整个input范围内移动滤波器。在上面的案例中我们使用了一个步幅为2,大小为5×5的滤波器。
tf.nn.bias_add方法把一个1维偏置数组加入到了矩阵的最后一维中。
完整代码请关注我的github:
Github链接
更多文章请关注我的个人网站:
weiweizhao.com
