05-00 CNN–卷积神经网络简介
前面我们介绍的神经网络都是把全部数据输入进去然后进行学习的,这个过程会掺杂很多无用的信息使得学习过程非常低效。但是如果我们已经知道我们要识别或者学习的是什么,我们可以有更高效的方法进行神经网络的学习。

前面我们介绍的神经网络都是把全部数据输入进去然后进行学习的,这个过程会掺杂很多无用的信息使得学习过程非常低效。但是如果我们已经知道我们要识别或者学习的是什么,我们可以有更高效的方法进行神经网络的学习。
当我们的训练数据集比较小时候经常会出现训练集准确率很高接近100%,但测试集准确率却很差的问题,这是过拟合(over fitting)现象。解决过拟合现象经常使用正则化(Regularization)与Dropout。
阅读更多
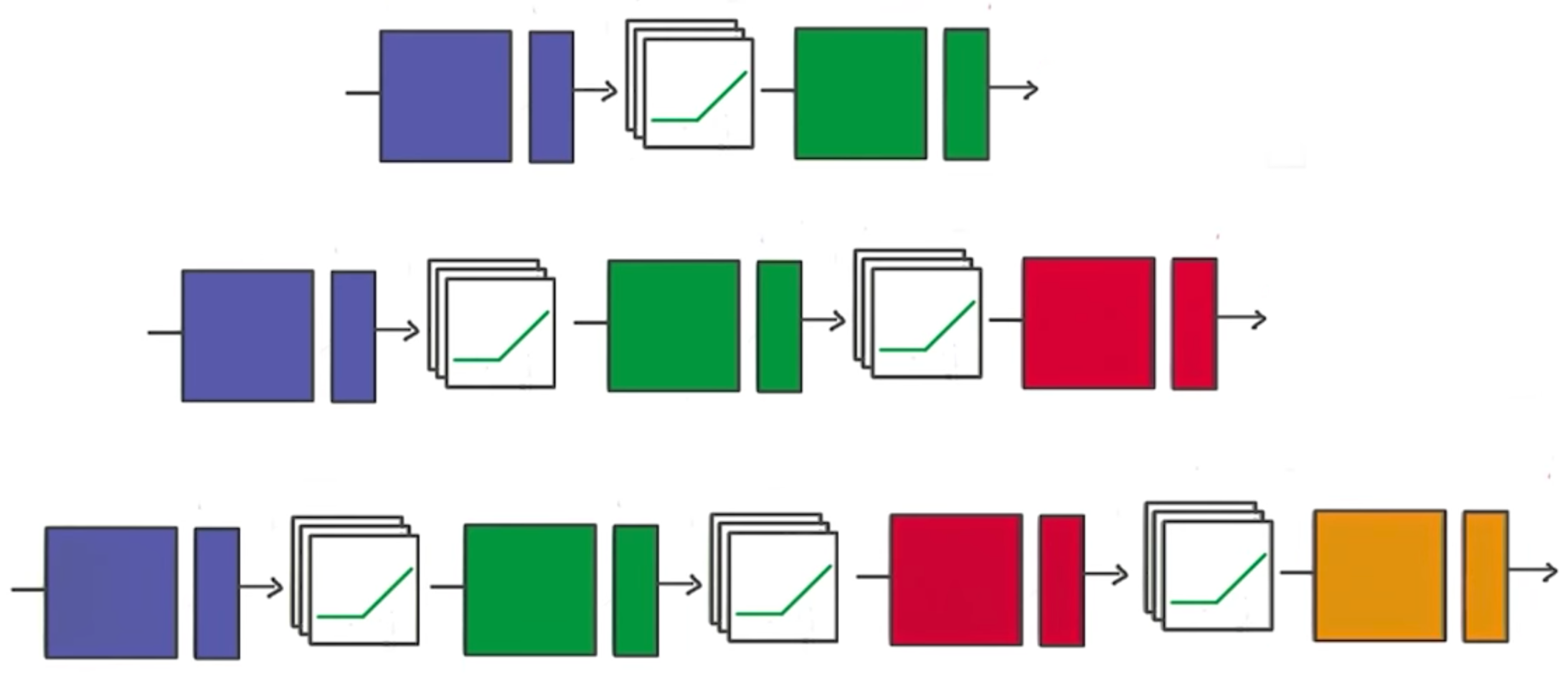
我们在上节课的训练中发现,每个回合训练的时间很久,加大训练回合之后所用的训练时间就更长了。一旦我们的程序结束,再次运行时原有的weight和bias信息全部消失了,又要重新训练。TensorFlow中设置了保存与加载的机制来解决这个问题。同时我们上节课建立的神经网络还不够“深”,只有一个隐藏层,这节课我们来加深神经网络。
阅读更多
之前我们已经通过TensorFlow建立了自己的分类器,现在我们将从基本的分类器转变为深度神经网络。我们以识别MNIST数据集中的手写数字作为目标,通过代码一步步建立神经网络。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(".", one_hot=True, reshape=False)
#MNIST数据集已经可以用one-hot编码的形式提供
import tensorflow as tf
# 学习的参数大家可以自行调节
learning_rate = 0.001
training_epochs = 20
batch_size = 128 # Decrease batch size if you don't have enough memory
display_step = 1
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
#隐藏层的数量也就是我们上一节中讲的ReLU的数量H,这个值也可以调节
n_hidden_layer = 256 # layer number of features
# 权重和偏置需要有两份,一份是wx+b;另一份是w1*ReLU输出+b1
weights = {
'hidden_layer': tf.Variable(tf.random_normal([n_input, n_hidden_layer])),
'out': tf.Variable(tf.random_normal([n_hidden_layer, n_classes]))
}
biases = {
'hidden_layer': tf.Variable(tf.random_normal([n_hidden_layer])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# tf Graph input
x = tf.placeholder("float", [None, 28, 28, 1])
y = tf.placeholder("float", [None, n_classes])
#由于输入的是28*28*1的图像,需要将它转变为784的一维数组输入
x_flat = tf.reshape(x, [-1, n_input])
#建立两层神经网络
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x_flat, weights['hidden_layer']), biases['hidden_layer'])
layer_1 = tf.nn.relu(layer_1)
# Output layer with linear activation
logits = tf.matmul(layer_1, weights['out']) + biases['out']
#GradientDescentOptimizer在TensorFlow入门那一章节讲过
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
#mnist.train.next_batch()每次返回一个训练集的子集
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
# Display logs per epoch step
if epoch % display_step == 0:
c = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print("Epoch:", '%04d' % (epoch+1), "cost=", \
"{:.9f}".format(c))
print("Optimization Finished!")
# Test model
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# Decrease test_size if you don't have enough memory
test_size = 256
print("Accuracy:", accuracy.eval({x: mnist.test.images[:test_size], y: mnist.test.labels[:test_size]}))
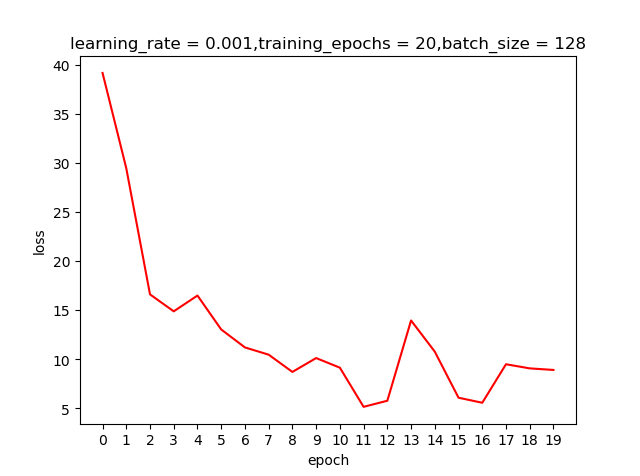
learning rate=0.001,epoch=20测试结果
learning rate=0.0001,epoch=20测试结果
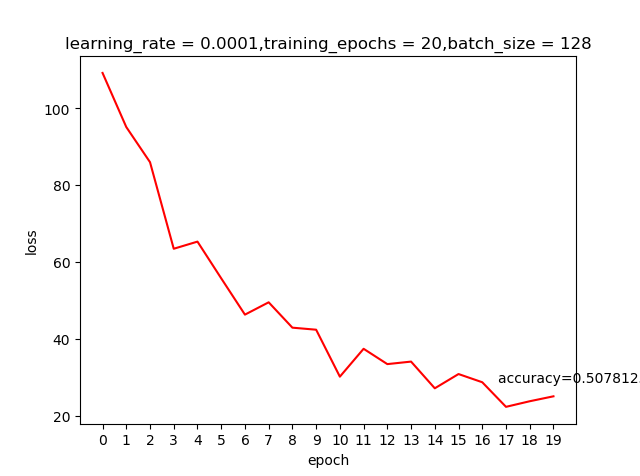
我们之前提到learning rate越大虽然学习越快,但精度可能并不好;上面这两个结果好像并不好解释,那是不是我们的学习回合不够多呢?那就把epoch加大到200看看有什么申请的反应
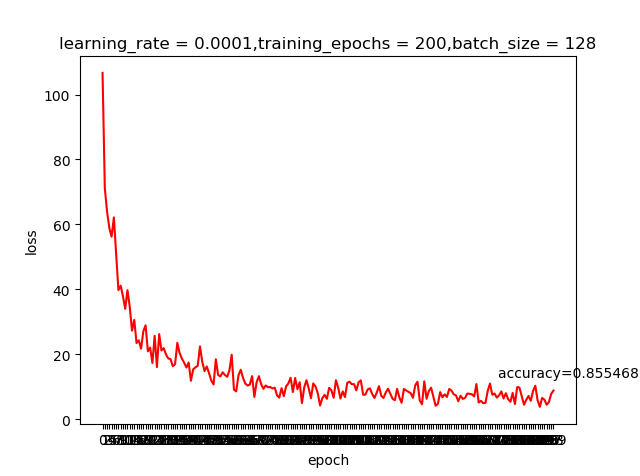
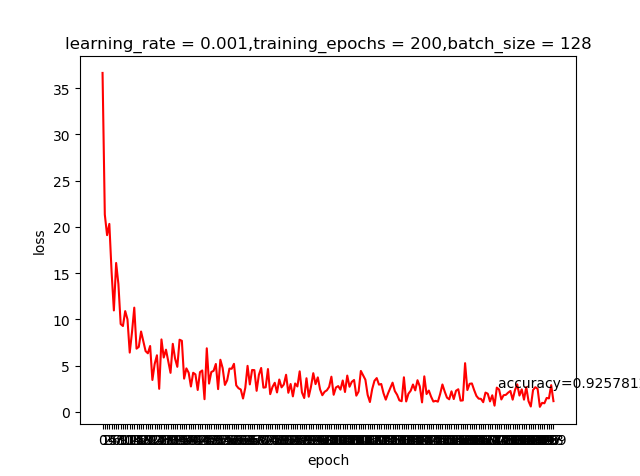
哈,这就是神经网络的神奇,调整一个小参数也会有很大的差别。感兴趣的同学可以把激活函数变成我们之前提到的sigmoid,看看有什么变化
03章节的TensorFlow入门我们建立了一个线性的模型Wx+b,实现了针对图片训练的简单逻辑分类器。这个功能看起来不错,但是功能却是十分有限。我们需要引入非线性的元素来实现更多的功能。
阅读更多
前面我们反复提到了使用梯度下降法逐渐调整神经网络的权重和偏置,使得神经网络输出的loss逐渐逼近最小值。同时,用于训练网络的训练数据集越大越好,越能提高神经网络预测的精度。这就有一个矛盾:梯度下降法每计算一次需要输入全部的数据计算误差,再反向求导。模型越复杂,输入数据越多,计算量就会飙升。
分类器经常会使用大量数据进行训练,但训练总是会带来一些问题:分类器可以非常好的识别那些见过的数据,一旦输入全新的数据,预测结果会变得非常差。这种情况在分类器中是普遍存在的,这是因为分类器总是偏向于记住这些训练数据而不是记住特征后推理新数据。我们将在这个章节讨论如何解决这种过拟合问题,以及选取多大的训练集比较合适。
阅读更多
经过上面几个章节的讲解,我们知道了使交叉熵减小的办法是梯度下降,需要对损失函数求导。我们掌握了导数工具之后将面临两个问题:我如何将图像输入到我的分类器中,以及我何时开始进行我的优化过程?本章节我们将会一一解答。
上一节我们训练了我们的第一个分类器,其中sandbox文件中有很多有意思的点可以探讨:softmax、one-hot encoding。这一章节我们将一一探讨这些知识点。
阅读更多
分类事一种给定输入和标记的任务,如下图的字母,每个字母有一个标签,说明它是什么。典型情况下我们会有很多样本,我们把它归类后交给分类器学习。当出现了全新的样本时,分类器的目标是指出这个新样本属于哪一类。虽然机器学习不仅仅包含分类,但是分类是我们机器学习的基础,例如:排序,目标检测,回归等算法都需要基于分类。本文将实现使用TensorFlow训练识别手写数字0,1,2.