
05-02 CNN-参数共享与维度
之前有小伙伴私信问我如何实现一只猫或狗出现在图像的不同位置也能正常识别出来。正如我们之前所看到的,图像中某一个特定小块的分类结果是由这个小块对应的权重w和偏置b决定的。如果我们希望图片左上角小块中的猫与右下角小块中的猫被相同的分类方法分类,那么左上角的小块和右下角的小块的权重w和偏置b都一致,这样它们的分类结果就会相同,这就是参数共享。
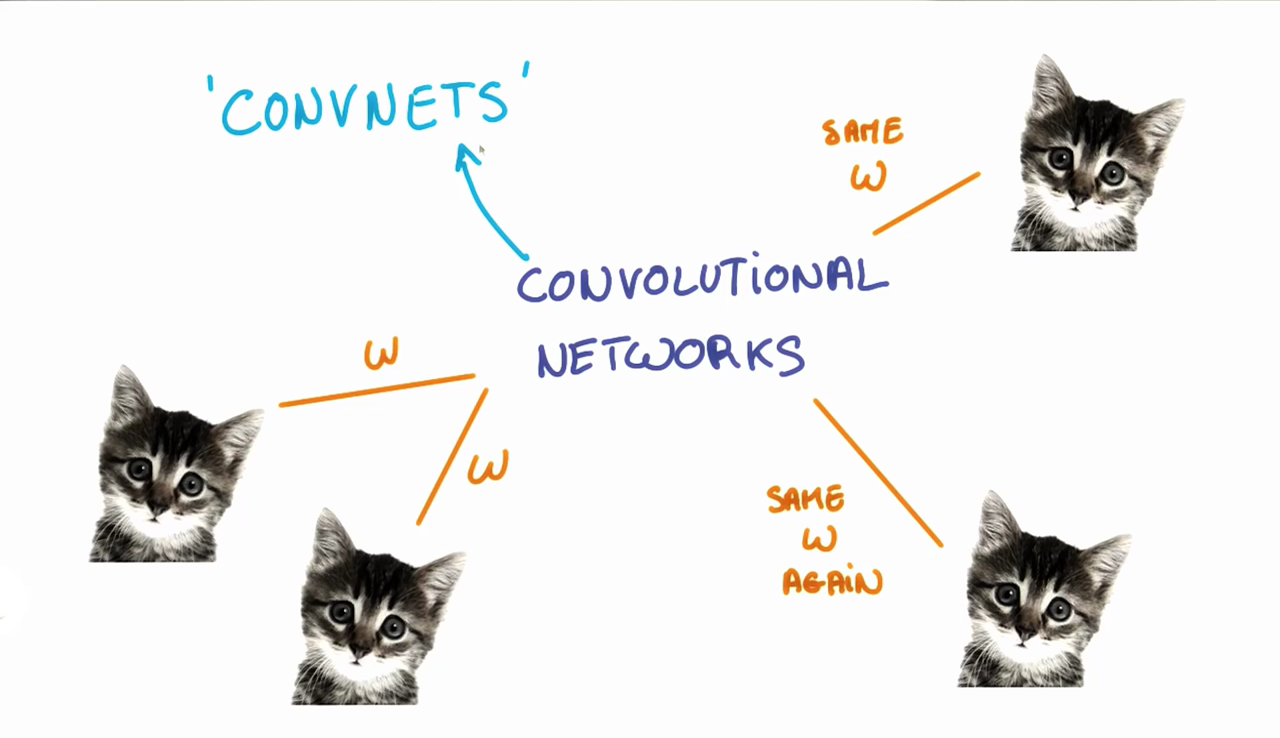
参数共享
上面我们说的正是卷积神经网络CNN正在做的。我们让输出层学习的权重和偏差在所有输入层的小块之间共享。要注意的是此时随着筛选器深度的增加,权重和偏置的数量仍然会增加,因为权重不会再输出通道之间共享。
参数共享的额外好处是带来较强的灵活性,如果我们没有在所有小块中共享相同的权重和偏差,我们就必须让每个小块和隐藏层神经元学习新的参数。如果输入是大分辨率的图像,学习效率将会大打折扣。因此,共享参数不仅有助于我们实现平移不变性,而且还为我们提供了一个更小、更可扩展的模型。
填充Padding
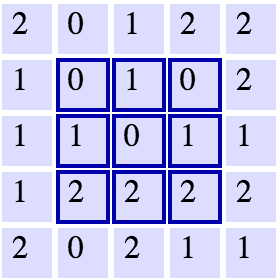
假设我们有一个如上图的5×5网格,在它上面应用一个3×3的滤波器,移动的步幅为1,那我们在下一层得到的长宽分别是多少?我们可以看到,我们最多可以在每个方向走3步,这样得到的是一个3×3的输出层大小。在这样的方案中,每个后续图层的长度和宽度都会降低。
在理想世界里,我们能够在各个图层之间保持相同的宽度和高度,以便我们能够继续添加图层,而不必担心维度缩小,从而保持一致性。我们如何才能做到这一点?一种方法是简单地将0的边框添加到我们原来的5×5图像中。如下图所示:
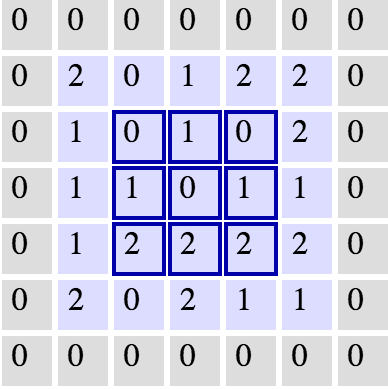
这样会扩展原输入到7×7,下一层的尺寸是5×5,保持了原有的尺寸。
维度Dimensionality
根据我们所学,我们可以计算出CNN的每一层所需神经元数量
假设给定:
1. 输入层宽度W,高度H
2. 卷积层尺寸F
3. 步幅为S
4. 填充边框为P
5. 滤波器数量K
我们可以计算输出层的宽度W_out和输出层高度H_out:
H_out = (H-F+2P)/S + 1
输出深度与滤波器数量相等
输出的大小是:W_out * H_out * D_out
知道每一层的维度有助于我们理解我们的模型究竟有多大,也可以让我们看到我们的滤波器大小和步幅是怎么影响神经网络的大小的。
练习
假设我们不使用参数共享,请计算我们的模型中会有多少个参数?模型设置如下:
H = height, W = width, D = depth
- We have an input of shape 32x32x3 (HxWxD)
- 20 filters of shape 8x8x3 (HxWxD)
- A stride of 2 for both the height and width (S)
- Zero padding of size 1 (P)
输出层
1. 14x14x20 (HxWxD)
计算过程
其中8 * 8 * 3是所有权重的数量,加1是偏置
每一个权重分配给输出的每一点,输出维度为14 * 14 * 20,由于参数不共享,我们要将这些参数乘起来,得到756560个参数的神经网络。
这仅仅是一个32*32的图像输入,想象一下如果我们输入一张1080P的图像呢?1920*1080
这就是参数共享带来的巨大好处。
如果我们保持上面输入而应用了参数共享,那么我们的神经网络中的参数数量是多少呢?
至于为什么这么计算请读者思考^_^
发表评论
Want to join the discussion?Feel free to contribute!