

07-00使用Keras进行交通标志识别
本章节我们开始学习一个新的高层次神经网络框架Keras。我们将通过代码一步步了解这个框架,弄清楚为什么我们需要这么一个框架来进行开发。
Keras是什么
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择Keras:
- 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
- 支持CNN和RNN,或二者的结合
- 无缝CPU和GPU切换
从这个官方的描述我们可以看出Keras并不是在生产环境中获得更高性能的深度学习框架,而是帮助我们快速开发的。
<--more-->
快速开发实例
我们将通过keras快速开发一个卷积神经网络,数据是我们之前提到的交通标志识别章节中所用到数据的一个子集。整个流程还是老样子:
– 导入数据
– 定义好网络
– 训练
– 输出结果
Keras中的神经网络
首先我们了解一些最基本的Keras中的概念
顺序模型
from keras.models import Sequential
#Create the Sequential model
model = Sequential()
keras.models.Sequential 类是神经网络的一个抽象模型。它可以提供一些神经网络经常用到的函数:fit(),evalute(),compile()。我们会在后续的代码中一一使用这些函数
层
keras中的层的概念与神经网络里面的层的概念是类似的。有全连接层,max pool层,激活函数层。可以通过add()函数添加一个层:
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
#Create the Sequential model
model = Sequential()
#1st Layer - Add a flatten layer
model.add(Flatten(input_shape=(32, 32, 3)))
#2nd Layer - Add a fully connected layer
model.add(Dense(100))
#3rd Layer - Add a ReLU activation layer
model.add(Activation('relu'))
#4th Layer - Add a fully connected layer
model.add(Dense(60))
#5th Layer - Add a ReLU activation layer
model.add(Activation('relu'))
Keras会自动调整输入层后的每一层的大小,这意味着我们只需要告诉Keras输入层的大小即可。上面的代码中model.add(Flatten(input_shape=(32, 32, 3)))将输入尺寸设置为(32, 32, 3),输出尺寸为 (3072=32 x 32 x 3)。第二层获取第一层的输出作为输入,然后设置输出为100.以此类推一直向下传递直到整个模型的输出。
小Tips 安装TensorFlow
pip直接安装的速度非常慢,需要几个小时才能完成,中间有各种意外因素可能导致中断,临时解决办法:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U tensorflow
distributed 1.21.8 requires msgpack, which is not installed
挑战开始-交通标志识别
数据集
感谢xxxy502的贡献,我们使用德国交通数据GSTRB,地址在这里:https://s3-us-west-1.amazonaws.com/udacity-selfdrivingcar/traffic-signs-data.zip 直接粘贴到迅雷下载。数据一共分为三部分Train,Test,Valid,作用一目了然,也就不过多展示。
检查数据
import pickle
import matplotlib.pyplot as plt
import numpy as np
class DataGenerate():
def __init__(self,path,mode):
# WAITING FOR CODE PACKAGE TO SYNC UP
with open(path, mode) as f:
self.data = pickle.load(f)
self.X_train, self.y_train = self.data['features'], self.data['labels']
print("Number of training examples =", self.X_train.shape[0])
print("Image data shape =", self.X_train[0].shape)
print("Number of classes =", len(set(self.y_train)))
def checkInitData(self):
n_classes = len(set(self.y_train))
n_data = self.X_train.shape[0]
rows,cols=4,12
fig,ax_array = plt.subplots(rows,cols)
plt.suptitle('RANDOM SAMPLES FROM TRAINING SET (one for each class)')
for classIndex,ax in enumerate(ax_array.ravel()):
if classIndex < n_classes:
cur_X = self.X_train[self.y_train == classIndex]
cur_img = cur_X[np.random.randint(len(cur_X))]
ax.imshow(cur_img)
ax.set_title('{:02d}'.format(classIndex))
else:
ax.axis('off')
plt.setp([a.get_xticklabels() for a in ax_array.ravel()], visible=False)
plt.setp([a.get_yticklabels() for a in ax_array.ravel()], visible=False)
plt.draw()
data_distribution = np.zeros(n_classes)
for c_rate in range(n_classes):
data_distribution[c_rate] = np.sum(self.y_train == c_rate)/n_data
fig_dis,ax_dis=plt.subplots()
col_width = 0.5
bar_data = ax_dis.bar(np.arange(n_classes)+col_width, data_distribution, width=col_width, color='b')
ax_dis.set_ylabel('PERCENTAGE OF PRESENCE')
ax_dis.set_xlabel('CLASS LABEL')
ax_dis.set_title('Classes distribution in traffic-sign dataset')
ax_dis.set_xticks(np.arange(0, n_classes, 5) )
ax_dis.set_xticklabels(['{:02d}'.format(c) for c in range(0, n_classes, 5)])
plt.draw()
plt.show()
littleData=DataGenerate(path='train.p', mode='rb')
littleData.checkInitData()
输出如下:
Number of training examples = 34799
Image data shape = (32, 32, 3)
Number of classes = 43
这里面一共有43种标志,所有数据放在32*32的图片中
其中的数据挑选一些观察:

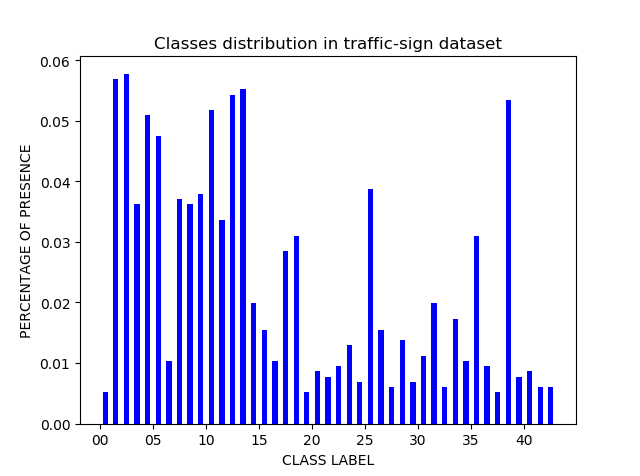
可以发现这些数据其实数据量偏差很大,后续我们为了取得更好的训练效果应该对训练数据进行优化(下篇文章)
搭建简单CNN网络测试
# Build Convolutional Pooling Neural Network with Dropout in Keras Here
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(32, 32, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.5))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(43))
model.add(Activation('softmax'))
(0): Host, Default Version
Epoch 1/10
870/870 [==============================] - 9s 11ms/step - loss: 2.1021 - accuracy: 0.3906 - val_loss: 17.3351 - val_accuracy: 0.1698
Epoch 2/10
870/870 [==============================] - 9s 10ms/step - loss: 1.2495 - accuracy: 0.6017 - val_loss: 21.9201 - val_accuracy: 0.1741
Epoch 3/10
870/870 [==============================] - 9s 10ms/step - loss: 0.9969 - accuracy: 0.6841 - val_loss: 25.7500 - val_accuracy: 0.1751
Epoch 4/10
870/870 [==============================] - 9s 10ms/step - loss: 0.8723 - accuracy: 0.7193 - val_loss: 28.8912 - val_accuracy: 0.1888
Epoch 5/10
870/870 [==============================] - 9s 10ms/step - loss: 0.7701 - accuracy: 0.7467 - val_loss: 31.2796 - val_accuracy: 0.1839
Epoch 6/10
870/870 [==============================] - 9s 10ms/step - loss: 0.6977 - accuracy: 0.7739 - val_loss: 33.5340 - val_accuracy: 0.1805
Epoch 7/10
870/870 [==============================] - 9s 10ms/step - loss: 0.6430 - accuracy: 0.7891 - val_loss: 36.2753 - val_accuracy: 0.1743
Epoch 8/10
870/870 [==============================] - 9s 10ms/step - loss: 0.6012 - accuracy: 0.8053 - val_loss: 38.0045 - val_accuracy: 0.1747
Epoch 9/10
870/870 [==============================] - 9s 10ms/step - loss: 0.5623 - accuracy: 0.8150 - val_loss: 38.3866 - val_accuracy: 0.1790
Epoch 10/10
870/870 [==============================] - 9s 10ms/step - loss: 0.5287 - accuracy: 0.8271 - val_loss: 40.0287 - val_accuracy: 0.1776
Testing
395/395 [==============================] - 1s 4ms/step - loss: 10.2955 - accuracy: 0.5903
loss: 10.295539855957031
accuracy: 0.5903404355049133
从以上结果可以看出,10次训练结束后识别准确率在82%左右,然而使用测试数据集发现准确率只有59%,说明模型的泛化可能不够。我们再用keras搭建一个Lenet,看看能不能有所改善
使用LeNet
#LeNet
def LeNet(X_train,Y_train):
model=Sequential()
model.add(Conv2D(filters=5,kernel_size=(3,3),strides=(1,1),input_shape=X_train.shape[1:],padding='same',
data_format='channels_last',activation='relu',kernel_initializer='uniform')) #[None,28,28,5]
model.add(Dropout(0.5))
model.add(MaxPooling2D((2,2))) #池化核大小[None,14,14,5]
model.add(Conv2D(16,(3,3),strides=(1,1),data_format='channels_last',padding='same',activation='relu',kernel_initializer='uniform'))#[None,12,12,16]
model.add(Dropout(0.5))
model.add(MaxPooling2D(2,2)) #output_shape=[None,6,6,16]
model.add(Conv2D(32, (3, 3), strides=(1, 1), data_format='channels_last', padding='same', activation='relu',
kernel_initializer='uniform')) #[None,4,4,32]
model.add(Dropout(0.2))
# model.add(MaxPooling2D(2, 2))
model.add(Conv2D(100,(3,3),strides=(1,1),data_format='channels_last',activation='relu',kernel_initializer='uniform')) #[None,2,2,100]
model.add(Flatten(data_format='channels_last')) #[None,400]
model.add(Dense(168,activation='relu')) #[None,168]
model.add(Dense(84,activation='relu')) #[None,84]
model.add(Dense(43,activation='softmax')) #[None,10]
#打印参数
model.summary()
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
return model
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 5) 140
_________________________________________________________________
dropout (Dropout) (None, 32, 32, 5) 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 5) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 16) 736
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 16) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 32) 4640
_________________________________________________________________
dropout_2 (Dropout) (None, 8, 8, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 6, 6, 100) 28900
_________________________________________________________________
flatten (Flatten) (None, 3600) 0
_________________________________________________________________
dense (Dense) (None, 168) 604968
_________________________________________________________________
dense_1 (Dense) (None, 84) 14196
_________________________________________________________________
dense_2 (Dense) (None, 43) 3655
=================================================================
Total params: 657,235
Trainable params: 657,235
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
870/870 [==============================] - 27s 31ms/step - loss: 2.4664 - accuracy: 0.2708 - val_loss: 14.3785 - val_accuracy: 0.1523
Epoch 2/10
870/870 [==============================] - 25s 29ms/step - loss: 1.0714 - accuracy: 0.6367 - val_loss: 19.7129 - val_accuracy: 0.1881
Epoch 3/10
870/870 [==============================] - 25s 29ms/step - loss: 0.5478 - accuracy: 0.8159 - val_loss: 16.7476 - val_accuracy: 0.1504
Epoch 4/10
870/870 [==============================] - 26s 29ms/step - loss: 0.3273 - accuracy: 0.8918 - val_loss: 18.8937 - val_accuracy: 0.1853
Epoch 5/10
870/870 [==============================] - 27s 31ms/step - loss: 0.2312 - accuracy: 0.9235 - val_loss: 21.7850 - val_accuracy: 0.1614
Epoch 6/10
870/870 [==============================] - 25s 29ms/step - loss: 0.1864 - accuracy: 0.9376 - val_loss: 19.7202 - val_accuracy: 0.1773
Epoch 7/10
870/870 [==============================] - 25s 29ms/step - loss: 0.1384 - accuracy: 0.9543 - val_loss: 22.2099 - val_accuracy: 0.1802
Epoch 8/10
870/870 [==============================] - 26s 30ms/step - loss: 0.1276 - accuracy: 0.9563 - val_loss: 19.1403 - val_accuracy: 0.1846
Epoch 9/10
870/870 [==============================] - 25s 29ms/step - loss: 0.1052 - accuracy: 0.9642 - val_loss: 20.3314 - val_accuracy: 0.1818
Epoch 10/10
870/870 [==============================] - 26s 30ms/step - loss: 0.0912 - accuracy: 0.9700 - val_loss: 19.9947 - val_accuracy: 0.1761
Testing
395/395 [==============================] - 7s 17ms/step - loss: 4.7895 - accuracy: 0.7243
loss: 4.7895002365112305
accuracy: 0.7243071794509888
从以上结果也可以看出,LeNet的训练准确率达到97%,而测试准确率依然不理想,这就要再继续优化了,下片文章我们再试试看泛化训练数据,优化网络是否可以继续提高测试集的准确率