
05-04 CNN-池化与1×1卷积
前面我们已经了解到了普通的卷积神经网络是什么样子。在本节将接触到更高级的操作:池化,1×1卷积,inception结构。池化是卷积神经网络中经常遇到的。池化层往往在卷积层之后,通过池化来降低卷积层输出特征向量,降低过拟合的概率。池化降低了各特征图的维度,但可以保持大部分重要信息。池化一般分为以下几种方式:Max pooling,mean pooling,加和。
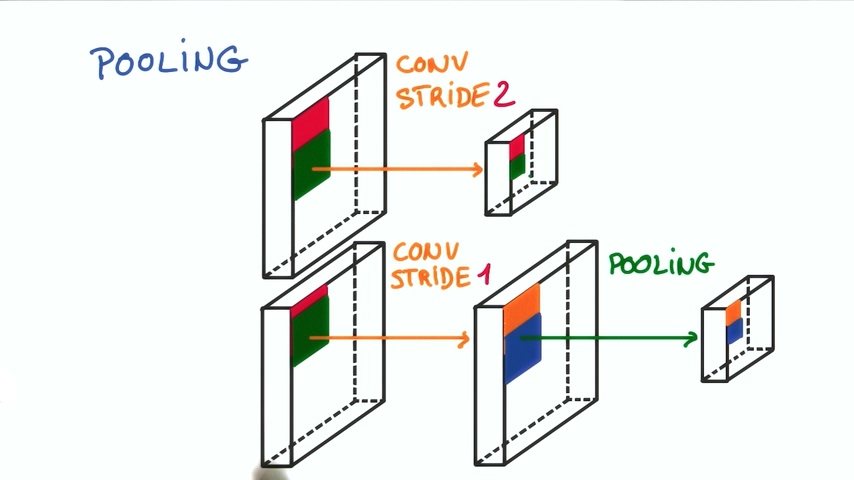
Max pooling和Mean pooling
我们定义一个空间邻域(比如,2×2的窗口),并从窗口内的修正特征图中取出最大的元素。
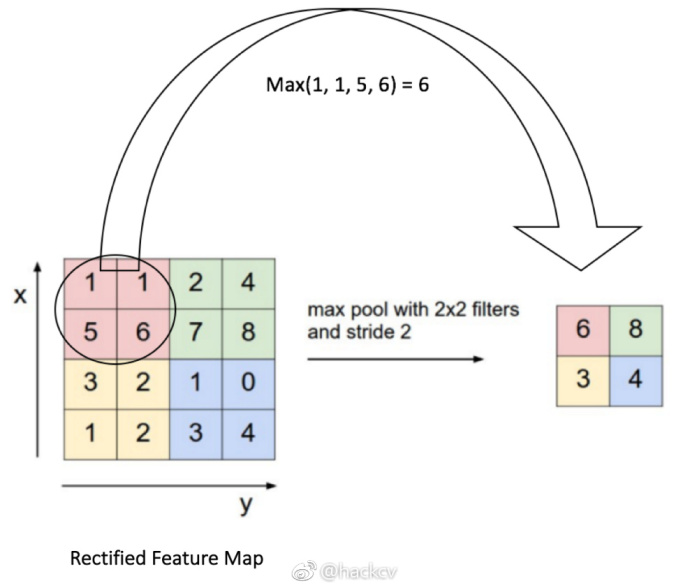
如上图所示,我们对卷积后的层进行池化操作,池化窗口大小定义为sizeX,池化窗口移动的步幅为stride,一般池化由于每一个池化窗口都不重复,所以sizeX=stride
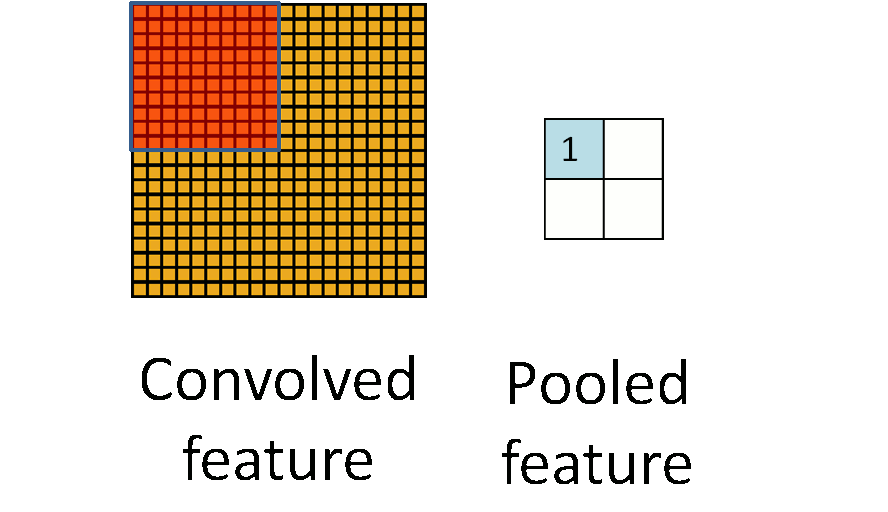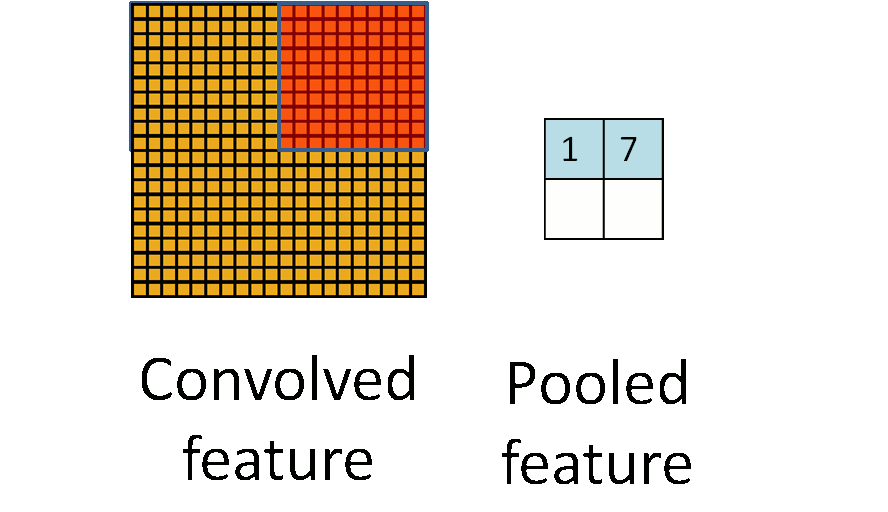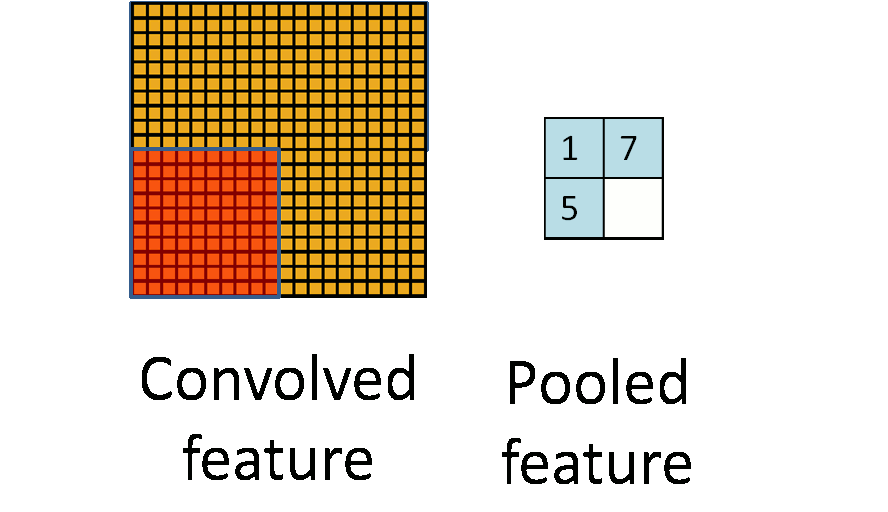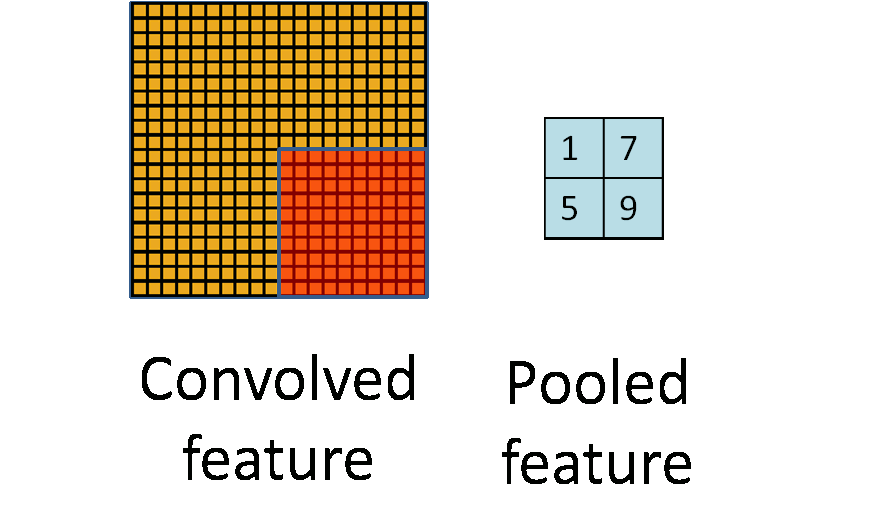
最大池化:选图像区域的最大值作为该区域池化后的值
平均池化:计算图像区域的平均值作为该区域池化后的值。
池化的优点有很多:
1. 使输入表示(特征维度)变得更小,并且网络中的参数和计算的数量更加可控的减小,因此,可以控制过拟合
2. 使网络对于输入图像中更小的变化、冗余和变换变得不变性(输入的微小冗余将不会改变池化的输出——因为我们在局部邻域中使用了最大化/平均值的操作。
3. 帮助我们获取图像最大程度上的尺度不变性(准确的词是“不变性”)。它非常的强大,因为我们可以检测图像中的物体,无论它们位置在哪里
加上池化后的神经网络
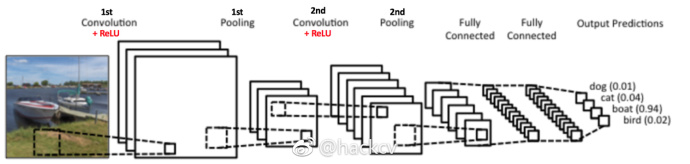
如上图所示,我们有两组卷积、ReLU&池化层——第二组卷积层使用六个滤波器对第一组的池化层的输出继续卷积,得到一共六个特征图。接下来对所有六个特征图应用 ReLU。接着我们对六个修正特征图分别进行最大池化操作。
这些层一起就可以从图像中提取有用的特征,并在网络中引入非线性,减少特征维度,同时保持这些特征具有某种程度上的尺度变化不变性。
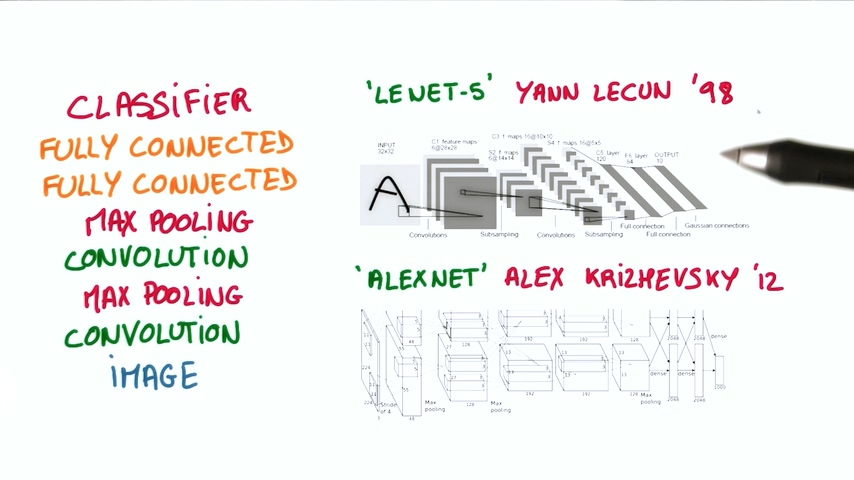
上图是两种比较经典的卷积神经网络
TensorFlow中的max pooling
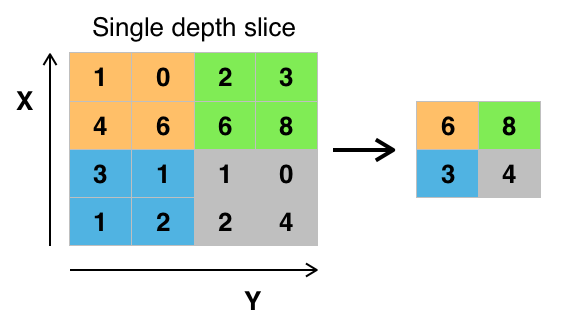
TensorFlow中提供了tf.nn.max_pool() 方法来对卷积层进行最大池化的操作
...
conv_layer = tf.nn.conv2d(input, weight, strides=[1, 2, 2, 1], padding='SAME')
conv_layer = tf.nn.bias_add(conv_layer, bias)
conv_layer = tf.nn.relu(conv_layer)
# Apply Max Pooling
conv_layer = tf.nn.max_pool(
conv_layer,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
1×1卷积
或许我们会疑惑,为什么我们要进行1×1的卷积?这不像我们之前说的选取图像的一块而仅仅是其中的一个像素,这有什么用呢?
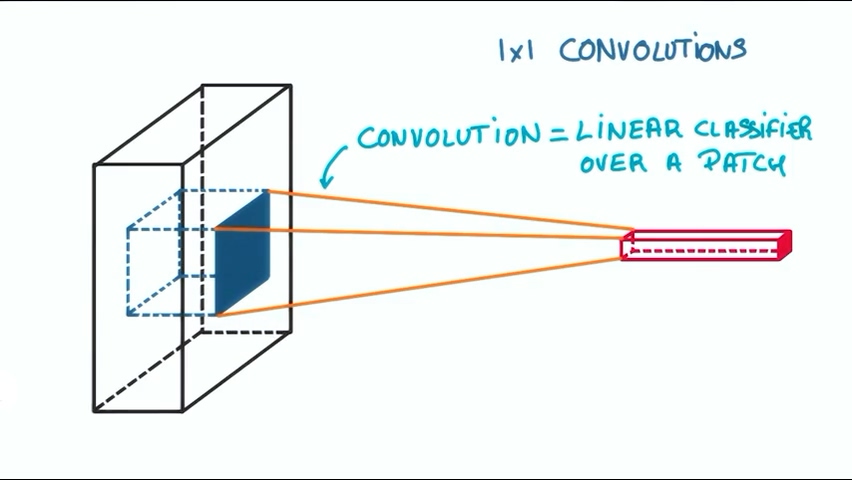
我们对图像的进行卷积操作得到的仅仅是一个针对一小块的线性的分类器,线性分类器的局限之前也说过。
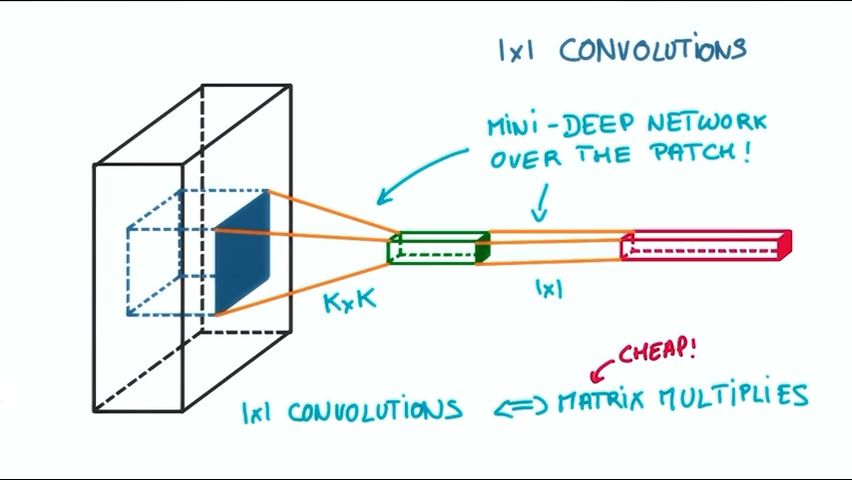
但如果我们在其中加入了一个1×1的卷积,这个分类器立马变成了一个非线性的分类器。最重要的是1×1的操作并没有复杂的卷积计算,仅仅是矩阵的乘法。整个分类器变成了非线性分类器,有助于提高分类的准确率。
通过应用池化和1×1卷积,卷积神经网络的识别准确率会有效提高,同时避免引入大量复杂的计算。这些方法是比较优秀的实践经验,值得借鉴。
发表评论
Want to join the discussion?Feel free to contribute!