
3-06 TensorFlow入门–随机梯度下降
前面我们反复提到了使用梯度下降法逐渐调整神经网络的权重和偏置,使得神经网络输出的loss逐渐逼近最小值。同时,用于训练网络的训练数据集越大越好,越能提高神经网络预测的精度。这就有一个矛盾:梯度下降法每计算一次需要输入全部的数据计算误差,再反向求导。模型越复杂,输入数据越多,计算量就会飙升。
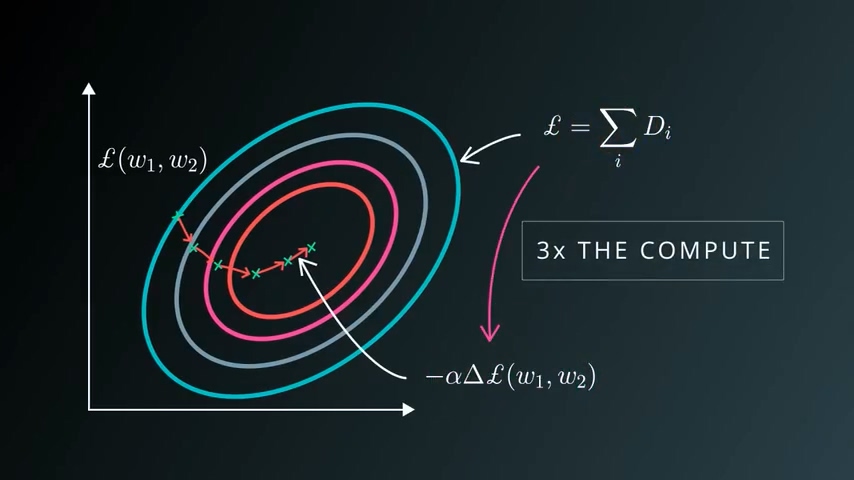
上图是一个经验数据,如果你计算loss的计算量为n,则求导的工作量为3n。之前我们也看到了,损失函数是非常巨大的,当我希望训练大量数据时,我的loss计算量会线性上升,而求导的计算量则是成倍上升。计算机的计算资源不能无限制满足这个要求,所以梯度下降法不能完全适用。
由于梯度下降法比较直接,我们一般经过一百多步的训练就可以逼近loss的最小值了。但由于它的计算量很大,所以我们不得不采用折衷的办法:不去计算梯度的真实值,而是梯度的估计值。
随机梯度下降 SGD
核心是每一步随机选取一小部分数据来计算loss及梯度。我们可以确定这种方法得到的估计值肯定离全部数据算出来的梯度值差很多,甚至可以说是惨不忍睹。但神奇的是,经过大量的训练次数,它还是可以逼近loss的最小值。
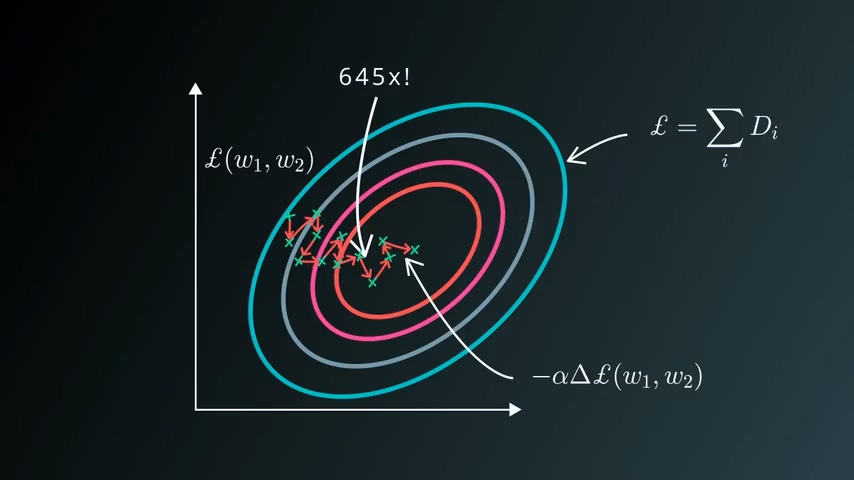
这是典型的时间换空间的做法。通过这种方法理论上可以无限制的增加我的样本数量,只要我每一步选取的足够随机,经过少量的计算即可完成训练的一个回合。增大回合数量,反复训练,即使每一步这个loss可能变大可能变小,还是可以一步步到达最优点。
随机梯度下降是深度学习的核心,因为随机梯度下降在数据和模型尺寸方面的兼容性非常好。我们可以同时拥有大量训练数据以及一个超大的神经网络,SGD可以轻易实现规模化训练。
动量和learning rate
我们之前已经学习了一些技巧,现在我们汇总一下:
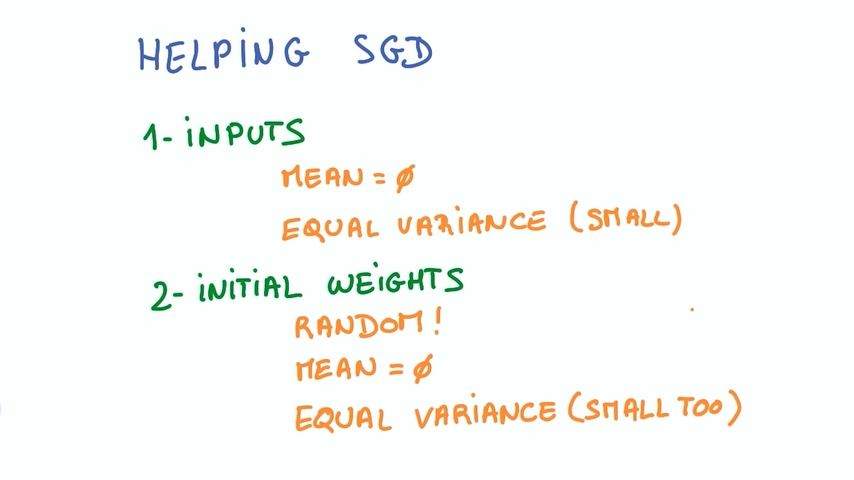
1. 输入
– 输入均值为0
– 方差相同
- 初始化
- 随机初始化
- 初始化均值为0
- 同方差
SGD的其他技巧
- 动量
我们之前提到过,随机梯度下降经过很多个小步骤计算loss和梯度,这些小步骤积累起来使得loss逐渐逼近最小值。这时候我们可以发现,其实前面走过的这些步骤计算出的梯度值的趋势指明了loss最小值的方向,这样可以简化我们的计算。
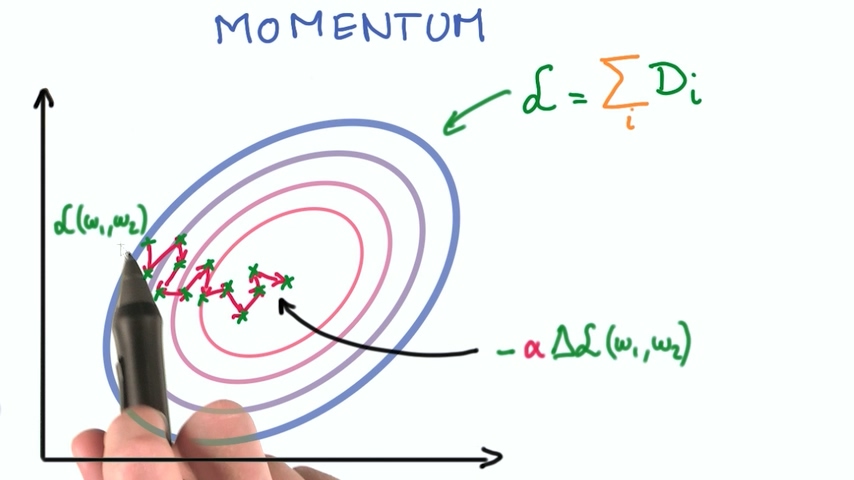
最省事的办法是前面几次的梯度值移动平均得到当前的梯度值,这种方法称为动量。这个技术比较有效,会有比较好的收敛性。
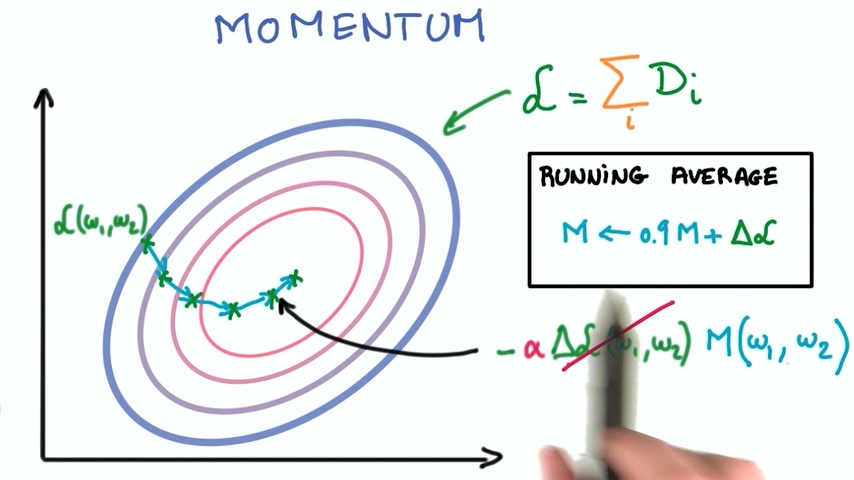
- learning rate衰减
当我们一开始学习的时候每一步梯度下降的快一些,快接近目标时我们的步子应该小一些。
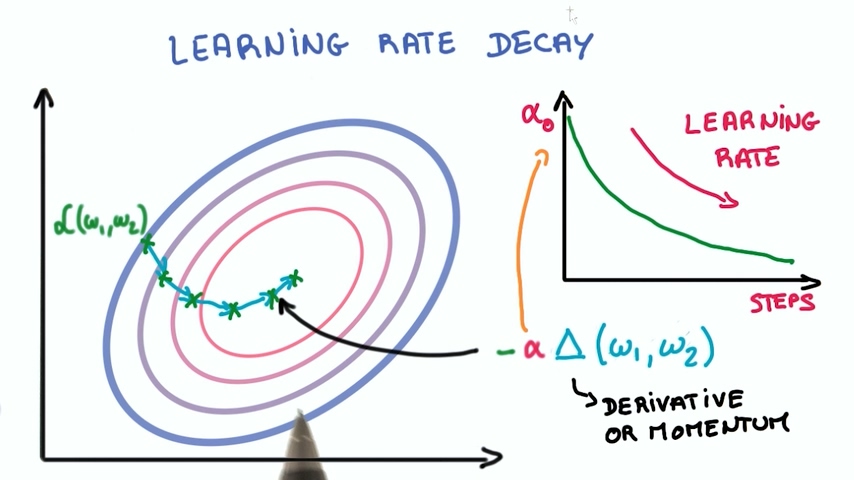
接近目标时的步子多小才是好的呢?目前还是一个研究方向,还没有定论。但是让learning rate随着训练逐渐减小确实是个非常有效的办法。有些使用指数衰减,有些使用线性衰减,核心都是让learning rate 随时间逐渐减小。
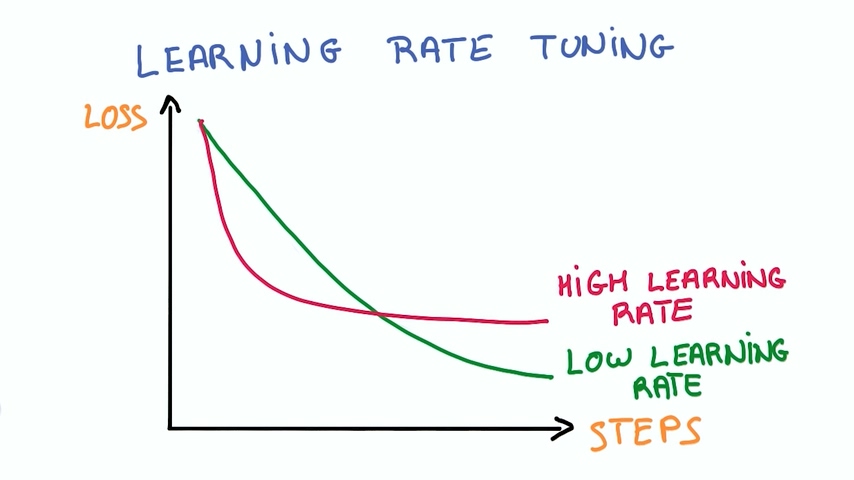
我们直觉上认为learning rate越大,我们每次学习的越多学习得越快,但实际并不是这样。我们可以看上图的曲线,使用高learning rate的训练在初始时虽然loss下降得很快,但是随着训练次数上升,它很快趋于稳定,并不能达到一个比较小的loss。反而使用低learning rate的训练可以更逼近0.这是深度学习上非常经典的曲线,学的是不是快跟最终学的好不好并没有直接关系。
SGD黑魔法

上面的参数都是我们可以在SGD中调节的参数,每调节一个参数都可以得到非常不一样的结果。
全流程总结
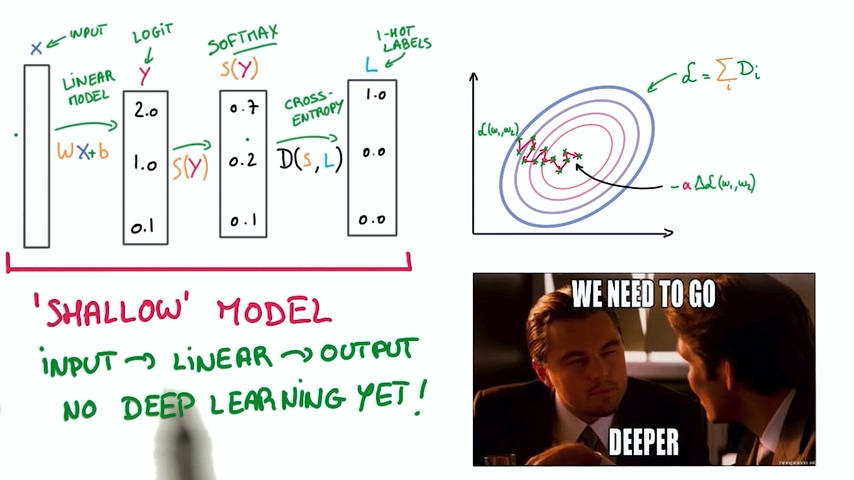
我们经过TensorFlow 入门这一章节学习了以下内容:
1. 建立一个分类器,包含线性模型,logit计算,softmax,交叉熵;得到loss
2. 使用随机梯度下降SGD逐渐使得loss逼近最小值
下一步我们将实现“深度”学习
发表评论
Want to join the discussion?Feel free to contribute!