
04-00 Deep_Neural_Network–线性模型的局限性
03章节的TensorFlow入门我们建立了一个线性的模型Wx+b,实现了针对图片训练的简单逻辑分类器。这个功能看起来不错,但是功能却是十分有限。我们需要引入非线性的元素来实现更多的功能。
线性模型中的参数
我们可以计算以下在03章节的神经网络中一共有多少个参数:
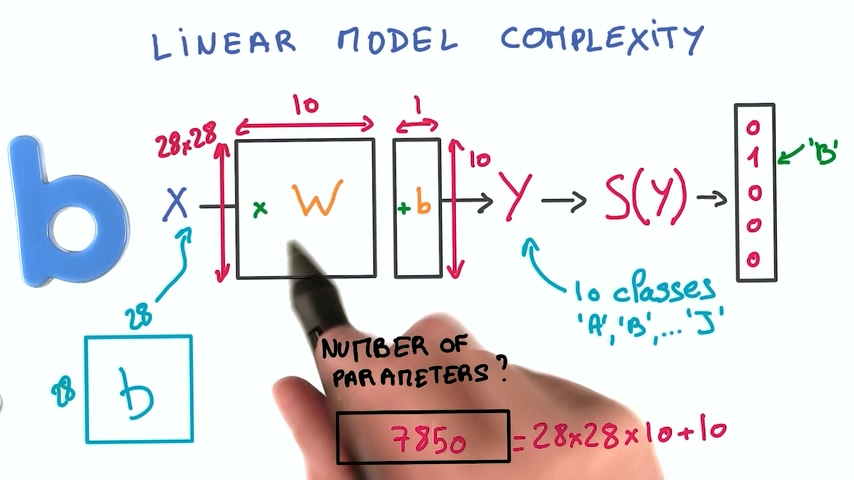
我们输入的图像是28* 28像素,输出是10个数字的概率,所以权重的另一个维度是10,再加上10个偏置,总共的参数数量是28*28*10+10=7850
线性模型的局限性
我们从上面的计算可以看出,对于线性模型,如果你有N个输入值,K个输出值,你的模型中就有(N+1)*k个参数
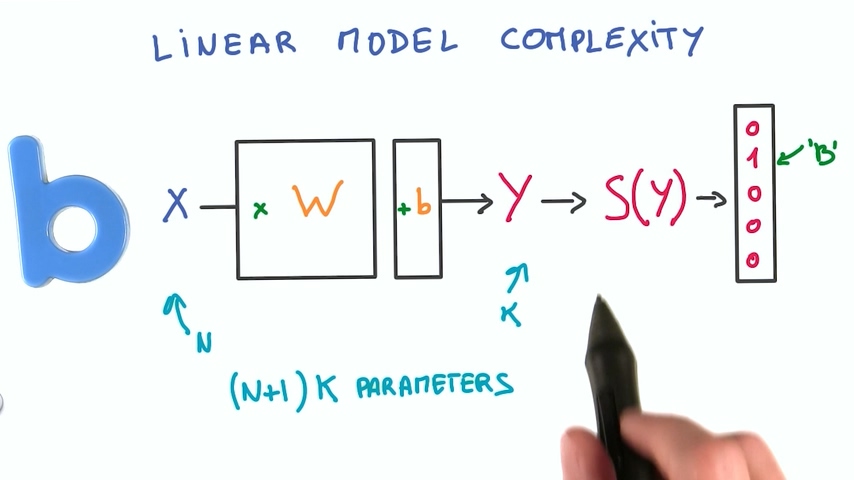
实际上我们要解决一个复杂问题我们需要的参数比这个要多得多。
还有一个问题:这个模型的公式是线性的,这意味着这个模型所能表达的关系式是很有限的的,例如:
– 关系式为两个输入相加,线性模型可以很好表示
– 关系式为两个输入相乘,线性模型无法表示

线性模型也有很多好处:
– 线性模型效率非常高,它的计算就是矩阵乘法(wx+b),而矩阵乘法我们用GPU来算非常方便
– 线性模型是非常稳定的,输入值小幅度变化,输出值同样是小幅度变化
– 线性模型的导数也很稳定,线性模型的导数是常数,没有比常数更稳定的吧?
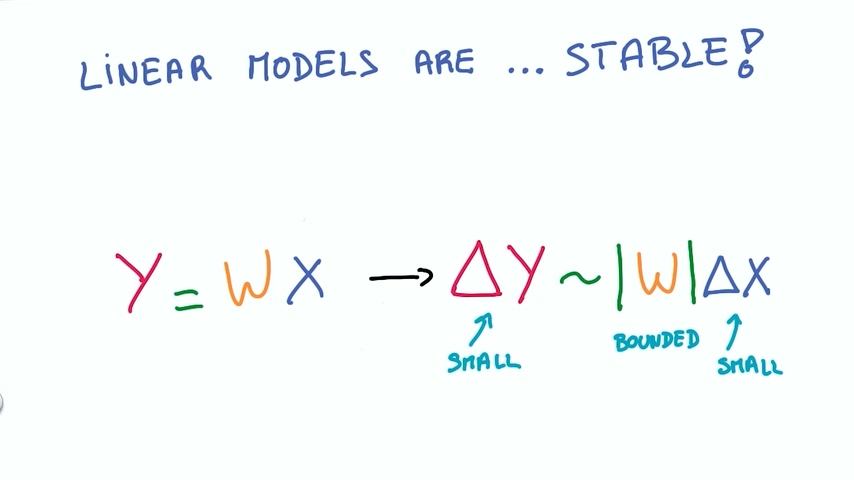
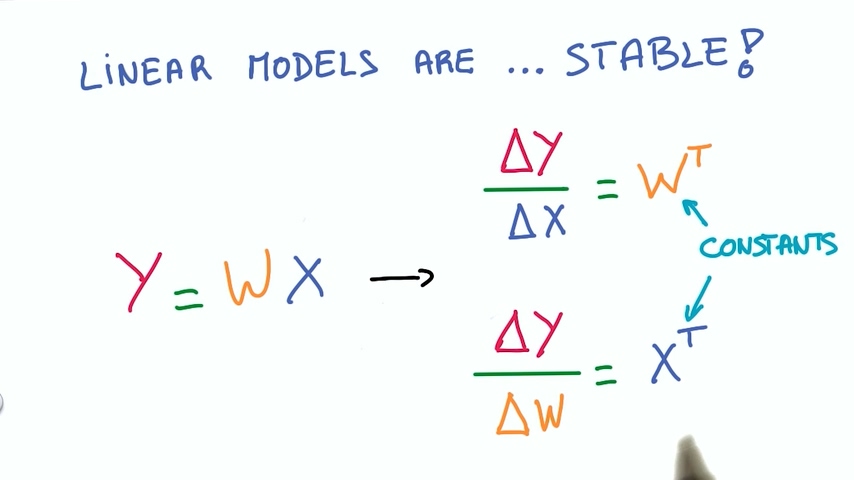
线性模型有这么多好处,我们也希望我们的参数还是保留在一个大的线性函数里面。但由于它有很多局限性,我们又希望模型是非线性的。
我们不能直接把线性函数的输入值不断相乘,因为这样得到的还是一个线性函数。

最简单的非线性函数
最简单的非线性函数是修正线性函数(Rectified Linear Unit),简称ReLU
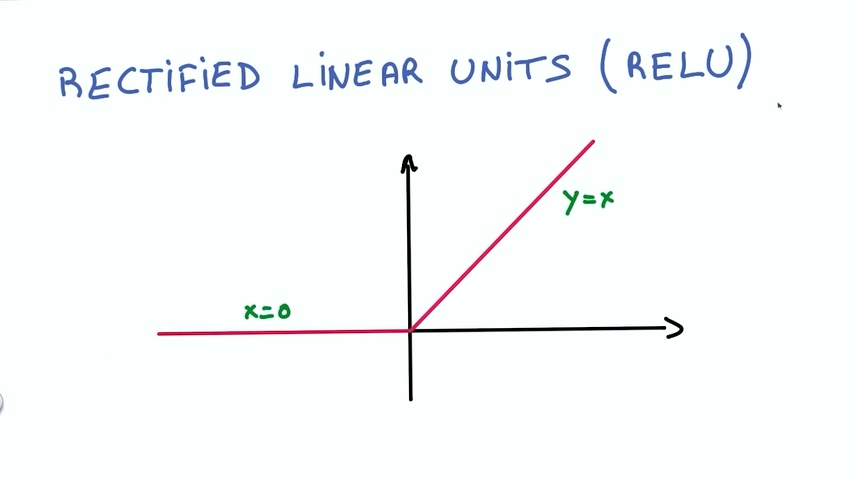
ReLU也非常稳定,它的导数是两个常数。
应用ReLU
我们把之前建立好的分类器拿过来使用,在分类器中加入ReLU,使得分类器变成一个非线性的分类器。
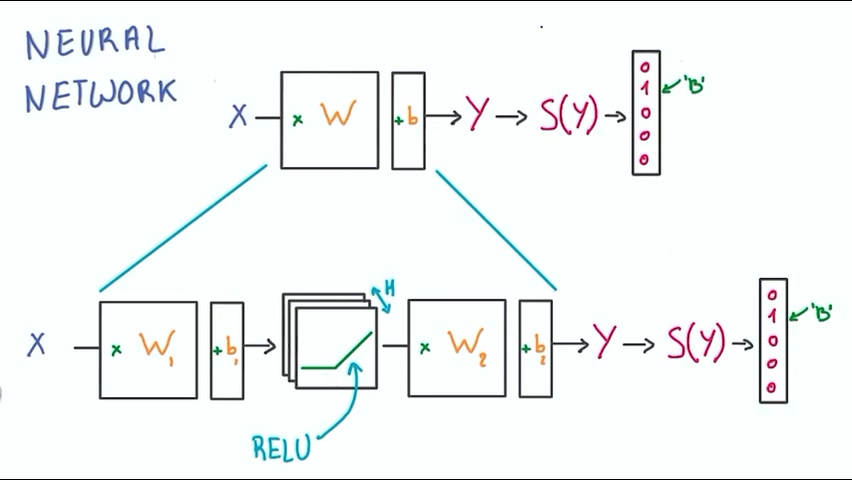
中间加入的ReLU数量为H,这个数值可以根据我们需要调整。
上面的模型经过这样一个小小的更改就变成了一个非线性的模型,同时还保留着线性模型的好处,这样我们成功实现了第一个深度神经网络。
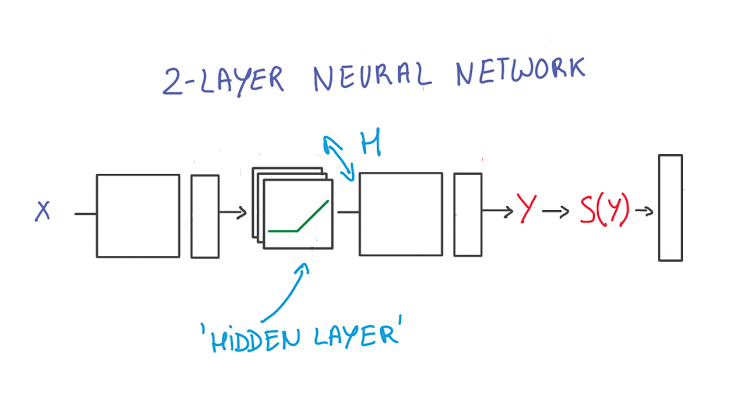
第一层将输入应用到wx+b,再将结果传输到ReLU,ReLU由于无法被外界观察到,因此被称为隐藏层。
第二层将这些中间输出再次应用到wx+b,最终由softmax来生成概率
TensorFlow中的ReLU
# Hidden Layer with ReLU activation function
hidden_layer = tf.add(tf.matmul(features, hidden_weights), hidden_biases)
hidden_layer = tf.nn.relu(hidden_layer)
output = tf.add(tf.matmul(hidden_layer, output_weights), output_biases)
ReLU其实是个激活函数,眼尖的同学肯定会想起我们之前学的sigmoid函数,我们在代码中比较一下这两个函数的不同
import tensorflow as tf
output = None
hidden_layer_weights = [
[0.1, 0.2, 0.4],
[0.4, 0.6, 0.6],
[0.5, 0.9, 0.1],
[0.8, 0.2, 0.8]]
out_weights = [
[0.1, 0.6],
[0.2, 0.1],
[0.7, 0.9]]
# Weights and biases
weights = [
tf.Variable(hidden_layer_weights),
tf.Variable(out_weights)]
biases = [
tf.Variable(tf.zeros(3)),
tf.Variable(tf.zeros(2))]
# Input
features = tf.Variable([[1.0, 2.0, 3.0, 4.0], [-1.0, -2.0, -3.0, -4.0], [11.0, 12.0, 13.0, 14.0]])
# TODO: Create Model
hidden_layer = tf.add(tf.matmul(features, weights[0]), biases[0])
hidden_layer = tf.nn.relu(hidden_layer)
logits = tf.add(tf.matmul(hidden_layer, weights[1]), biases[1])
# TODO: Print session results
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("relu result:")
print(sess.run(logits))
sigmoid_hidden=tf.add(tf.matmul(features, weights[0]), biases[0])
sigmoid_hidden= tf.nn.sigmoid(sigmoid_hidden)
sigmoid_logits = tf.add(tf.matmul(sigmoid_hidden, weights[1]), biases[1])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("Sigmoid result:")
print(sess.run(sigmoid_logits))
测试结果如下:
relu result:
[[ 5.11 8.440001]
[ 0. 0. ]
[24.010002 38.239998]]
Sigmoid result:
[[0.99391145 1.5915966 ]
[0.00608859 0.00840352]
[1. 1.6 ]]
激活函数并没有绝对的优劣之分,关于这两种激活函数的不同可以参考大神的博客:
深度学习:激活函数的比较和优缺点,sigmoid,tanh,relu
发表评论
Want to join the discussion?Feel free to contribute!