
3-05 TensorFlow入门–过拟合以及训练集的大小
分类器经常会使用大量数据进行训练,但训练总是会带来一些问题:分类器可以非常好的识别那些见过的数据,一旦输入全新的数据,预测结果会变得非常差。这种情况在分类器中是普遍存在的,这是因为分类器总是偏向于记住这些训练数据而不是记住特征后推理新数据。我们将在这个章节讨论如何解决这种过拟合问题,以及选取多大的训练集比较合适。
衡量分类器性能
我们输入一大堆带标签的数据,然后我们启动分类器,看看有多少个是正确识别的,通过多次训练使得针对训练数据集本身的预测误差达到最小。这时候我们输入一个全新的数据,从未在训练集中出现过的数据,这时候我们得到的预测结果会很糟糕。为什么会这样?
记忆与分类
最简单的分类器是记住每一个输入的数据,以及对应的标签。下一次输入数据的时候把输入数据与记忆中的所有数据进行对比,找到对应的标签并输出结果,这种分类器的精度是100%。而一旦遇到完全没有见过的数据,这个分类器就懵了。这就不是一个好的分类器了。这个问题是分类器记住了训练集但没有对新数据的推理能力。这不仅仅是一个理论上的问题,每一个分类器其实都会有这个记忆的倾向。我们的工作应该是帮助分类器具备推理的能力。==所以我们衡量分类器的性能应该由衡量记忆能力转变为衡量推理能力==
最简单的办法是采用全部训练数据集的一个子集作为测试集,这个测试集必须没有用于训练。测试的结果用来衡量分类器的推理能力。训练本身是不断试错然后纠正的过程,我们训练好分类器,用测试集衡量它的性能,然后调整分类器,再重复测试,反复进行指导它的性能指标达到了最高。
这就解决了推理能力不足的问题吗?其实并没有,每次你决定用哪种分类器,调整哪些参数都会间接影响分类器,相当于测试的数据集通过开发人员的眼睛间接训练了分类器,人为干预了分类器的决策,还是一个记忆的过程,这个分类器在实际环境中肯定会吃亏。
解决这个问题有一种比较简单的方法就是把再取一个小训练集作为一个黑盒,开发人员看不见。在最终决定部署到实际环境之前不去测试这个黑盒的结果。这个测试结果可以比较好的体现你的分类器性能。
如何选取数据集的大小?
深度学习过程中有非常多的参数可以调节,开发人员比较像炼金术士,不断调节这个调节那个,减小训练误差,这很容易就产生了过拟合问题。目前解决这个问题的方法是交叉验证。可以参考大神的博客为什么要用交叉验证
这个过程中我们要思考:我的测试和验证数据集要选多大呢?
想象一个只有六个数据的验证数据集,如果我们第一次测试有4个正确的,正确率66%;而修改参数之后变成5个正确的,正确率83%。看起来这个正确率提升非常明显,我们可以认定我们的修改是有效的吗?答案是否定的
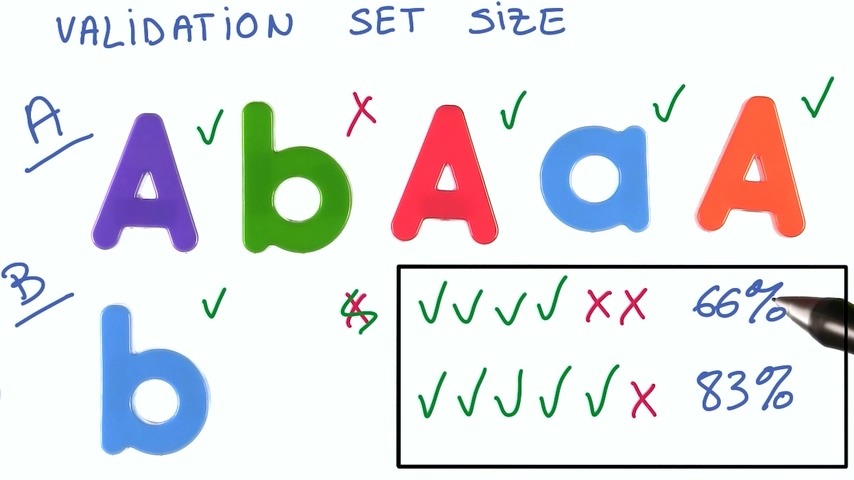
因为只有一个预测结果改变了,它很可能只是一个噪声的影响,并不能证明你的修改真的有效。测试数据集越大,噪声越小,测量结果越准确。
“30准则” 经验
统计学上有个经验数据,如果你的修改影响了验证集上的30个实例的改变,那你的修改可以认为是有效的。
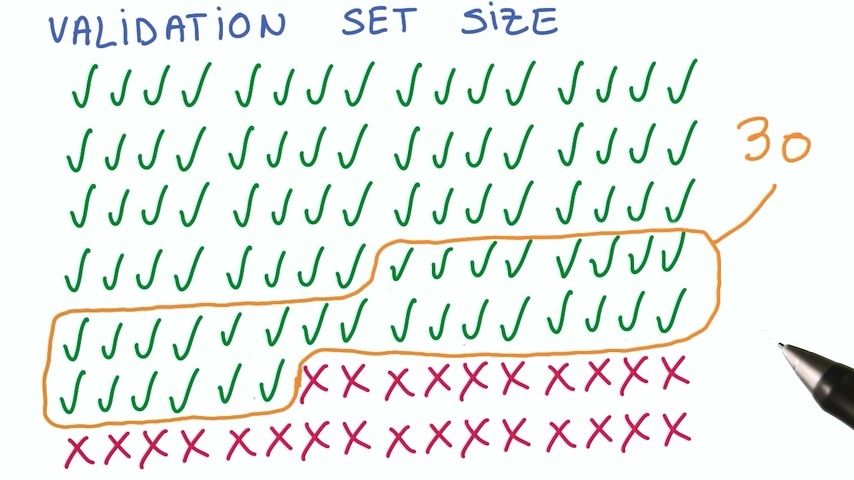
推荐数据集大小不小于30000个
为什么选择30000呢?根据我们的“30准则”,30000的0.11%是30,如果我提升了0.11%的精度,那这就是一个强烈的信号说明我的修改是有用的。这使得准确率的第一个小数位是个有效数字。给你足够的分辨率去看到小的改进。

数据集越大,对精度的有益效果越明显。如果你实在找不出这么多的训练数据,那么就要使用交叉验证了

发表评论
Want to join the discussion?Feel free to contribute!