
3-04 TensorFlow入门-输入与优化
经过上面几个章节的讲解,我们知道了使交叉熵减小的办法是梯度下降,需要对损失函数求导。我们掌握了导数工具之后将面临两个问题:我如何将图像输入到我的分类器中,以及我何时开始进行我的优化过程?本章节我们将会一一解答。
数值稳定性
数值稳定性是我们必须去关注的话题,因为计算机在处理极大数值和极小数值相加时总是会引入误差,而这个误差恰恰会引起我们分类器的错误。
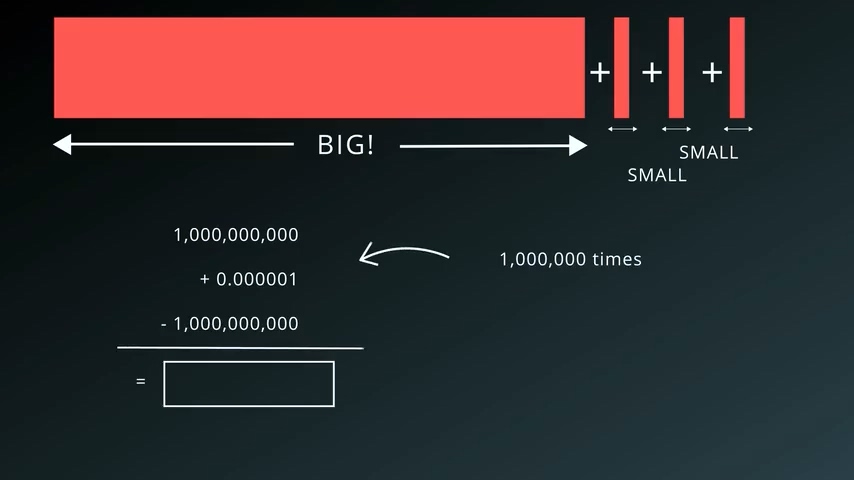
我们可以做以下的实验,在Python中运行这段代码:
a=1000000000
for i in range(1000000):
a+=1e-6
print(a-1000000000)
按照预期,输出的结果是1.0,但是经过这些运算之后我们发现其实输出结果是0.953674316406…,然后我们继续修改a初始值为更大的值,发现误差会越来越大。
我们之前也发现了损失函数的输入矩阵其实非常大,需要经过的计算很多,我们希望这些参与计算的数永远不要太大或者太小,这就是数值稳定性的意义。其中一个比较好的方法是使我们所有的输入变量均值为0,并且尽可能同方差。
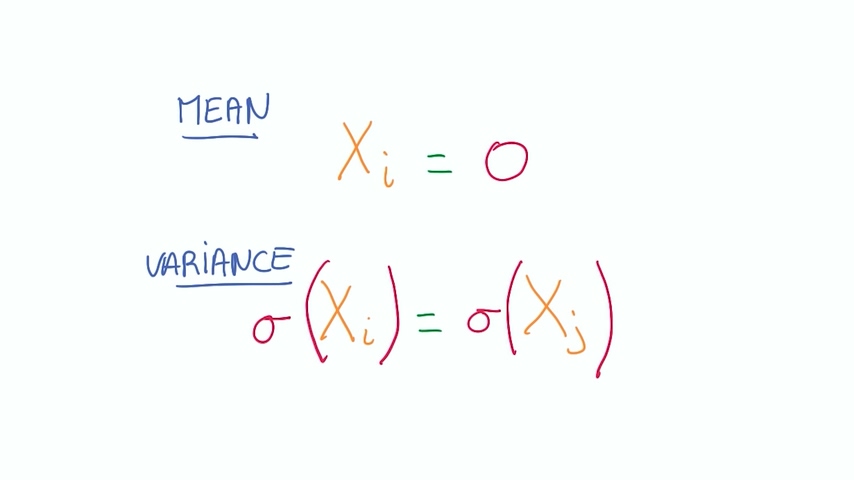
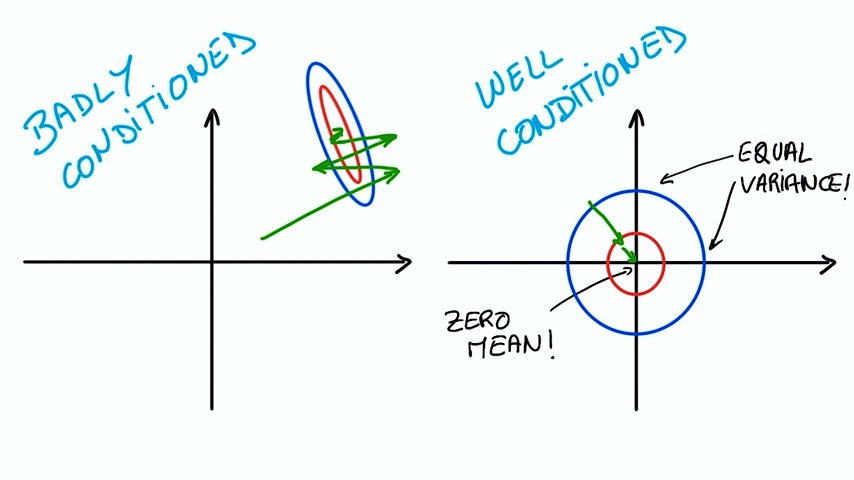
这样做的好处除了可以保持数值稳定性之外还可以让我们在做优化时有较好的数学基础来快速达到优化结果。不同方差和均值意味着优化器需要搜索很多次才能够寻找到最优解。
处理图像输入
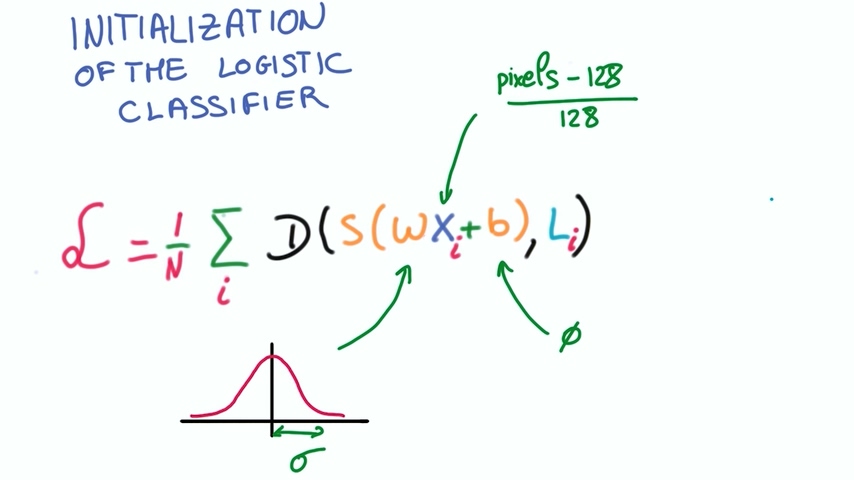
图像由像素组成,像素表示方法分别为RGB,我们将像素点数值取出,分别将RGB做如下处理

这样处理后的输入并没有改变图像的内容,但是它使我们更容易优化。
初始化w和b
同时我们也希望我们的权重w和偏置b的初始化遵循从均值为0标准差为sigma的高斯分布中随机抽样。

sigma的数值决定了最优化过程中在初始化时的输出数量级。由于输出又被softmax处理,这同时也决定了初始化时的概率分布的峰值。
– 大的sigma意味着概率分布有较大的峰值,分类器很武断
– 小的sigma意味着概率分布比较平均,分类器很谨慎
通常我们都希望开始于一个比较不确定的概率分布,随着训练的过程让分类器变得越来越自信。所以我们应该选取小的sigma给我们的参数进行初始化。
优化过程
我们现在已经确定了分类器的全部输入以及分类器公式,有了损失函数。我们将整个训练数据集输入到分类器中,计算整个数据集的损失平均值。
然后我们使用优化包对损失函数对权重和偏置的求导,进行反向传播,重复这两个过程,最终得到最优化的w和b。
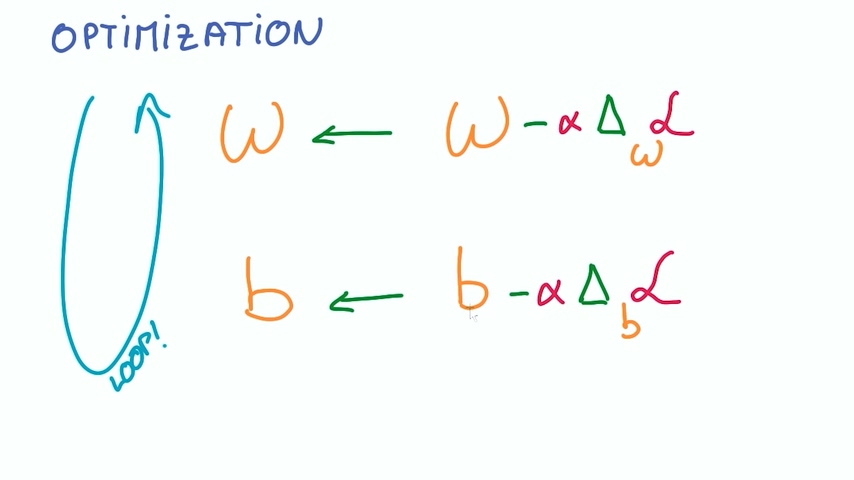
发表评论
Want to join the discussion?Feel free to contribute!