
3-03 TensorFlow入门-One_Hot编码与交叉熵
上一节我们训练了我们的第一个分类器,其中sandbox文件中有很多有意思的点可以探讨:softmax、one-hot encoding。这一章节我们将一一探讨这些知识点。
Softmax
上一章节我们知道,神经网络的输出是每一个预测值对应的概率值,这个概率值是通过Softmax函数将logits转换过来的。
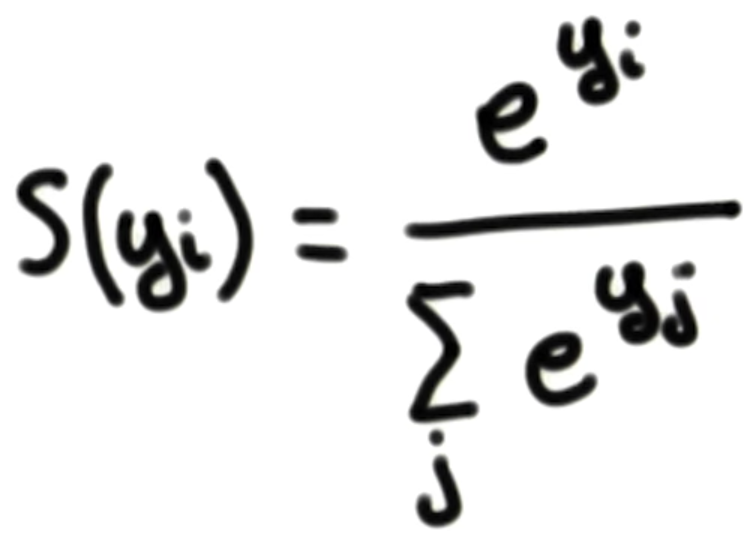
我们可以实现这样的函数,“e”是一个常数,接近于2.718 .使用上面等式始终返回一个正数,这有利于我们解决负数输入带来的问题。等式的分母是所有e^(输入y)的值之和,确保所有输出概率之和为1.
代码实现
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
return np.exp(x) / np.sum(np.exp(x), axis=0)
TensorFlow中的Softmax
x = tf.nn.softmax([2.0, 1.0, 0.2])
one-hot encoding
对于Softmax函数,它的输出中接近预测值的对应的概率较大,其余概率较小。换句话说如果我们把这个输出放大,那么我们的分类器会对它的预测结果非常自信,而如果我们缩小,则分类器的输出就不那么自信了。
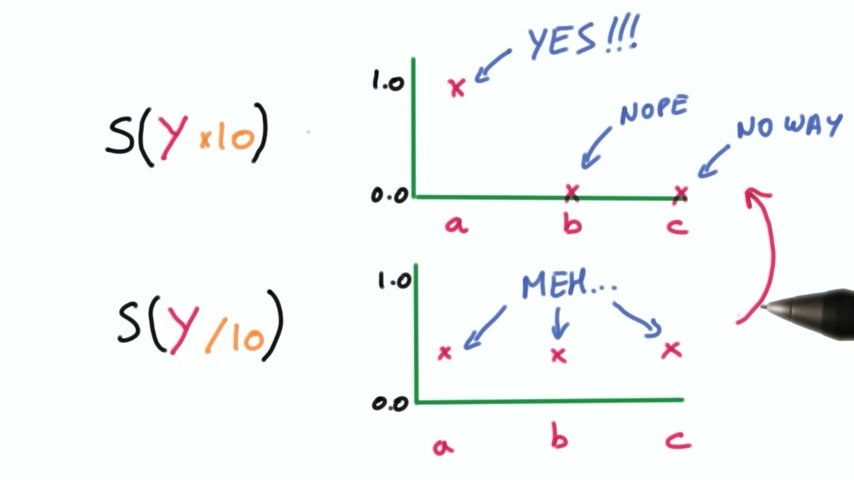
我们的目标是在开始学习时让分类器不那么自信,随着时间推移逐渐变得更加自信。这个过程如何用数学实现呢?
数学实现
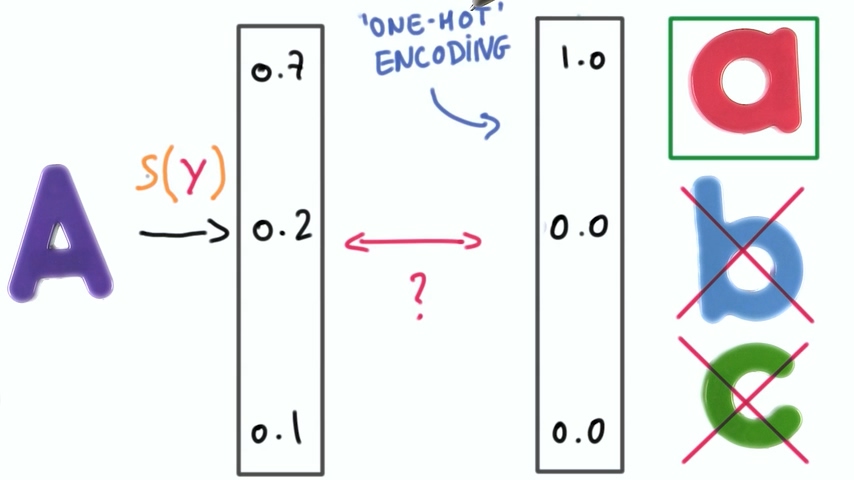
让正确的分类概率接近于1,也可以说用一个表示结果的向量,(分类器认为的)正确的分类概率直接置为1,其余概率置为0. 这就是我们所说的one-hot 编码
交叉熵Cross Entropy
one-hot编码在大多数情况下可以较好工作,但如果我们将分类器应用于有大量的(例如成千上万)的分类时,one-hot编码的向量将会变得非常巨大。而它的大部分数值都为0,这会使得计算效率很低。为了解决这一问题,我们引入交叉熵的概念。
我们希望通过简单的比较两个向量就能计算出两个向量之间的距离,这样我们只需要存储这个距离而不是整个one-hot编码,减小向量。
这两个向量一个是分布概率向量,来自于分类器的softmax函数,代表样本属于不同类别的概率;另一个是这个分布概率向量经过one-hot编码之后的one-hot编码向量表。
交叉熵是度量两个向量之间距离的方法之一,其公式如下:

需要注意的是由于存在着对数运算,所以交叉熵公式中的两个变量顺序是不能对换的。由于one-hot编码后的向量中存在大量的0,不能作为对数输入,所以对数输入必须是分布概率向量。
我们把整个过程串起来就是下面的图片所显示的:
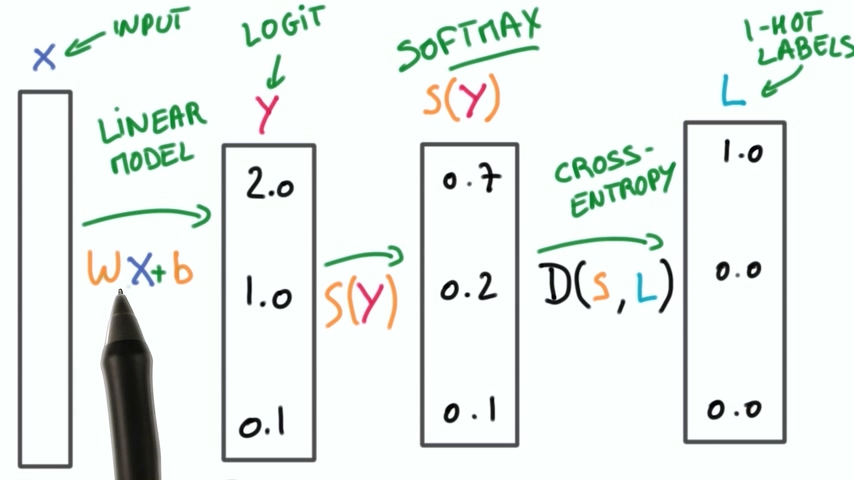
- 输入经过线性函数得到logit
- logit通过softmax函数得到分布概率向量
- 分布概率向量经过one-hot编码得到ont-hot向量
- 使用交叉熵计算两个向量之间的距离
以上整个过程称之为逻辑多项式回归
交叉熵在TensorFlow中的实现
交叉熵函数如下:
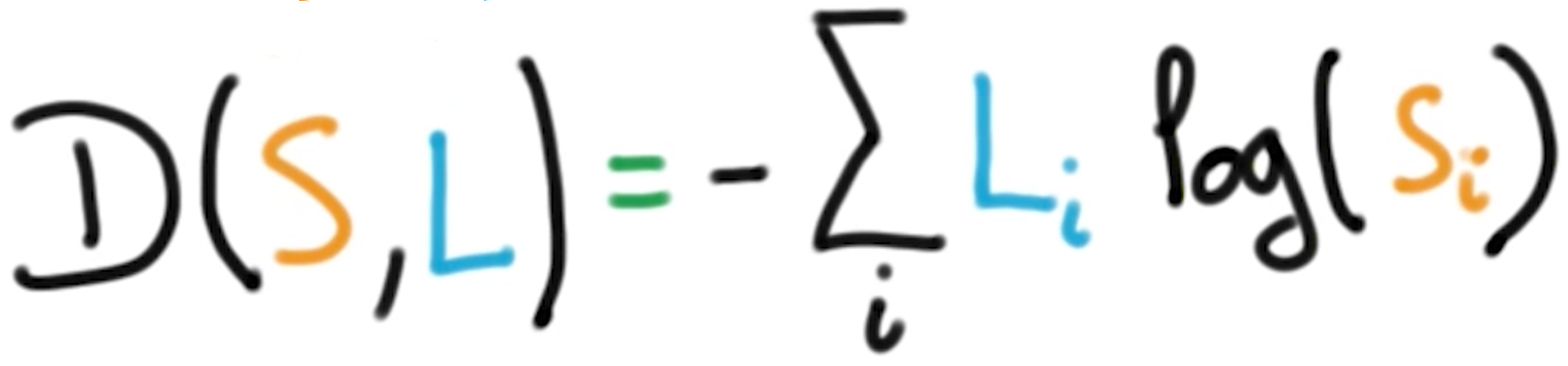
其中会用到求和函数,对数函数,对应的TensorFlow方法如下:
– tf.reduce_sum()
– tf.log()
测试代码:
import tensorflow as tf
softmax_data = [0.7, 0.2, 0.1]
one_hot_data = [1.0, 0.0, 0.0]
softmax = tf.placeholder(tf.float32)
one_hot = tf.placeholder(tf.float32)
# ToDo: Print cross entropy from session
cross_entropy = -tf.reduce_sum(tf.mul(one_hot, tf.log(softmax)))
with tf.Session() as sess:
print(sess.run(cross_entropy, feed_dict={softmax: softmax_data, one_hot: one_hot_data}))
最小化交叉熵
我们的目标是修改权重w和偏置b,使得正确分类的交叉熵(距离)足够小,错误分类的交叉熵(距离)足够大
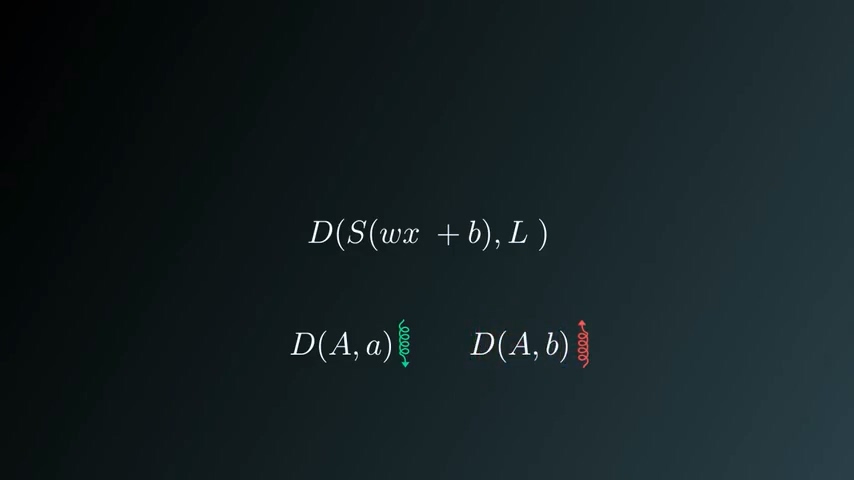
其中的一个方法使我们求出所有训练集样本和所有类别的距离之和,这个值称之为训练损失(Training Loss)。这个函数称为惩罚函数,这个函数求出了所有训练集样本的交叉熵的均值。


我们的目标是尽可能减小交叉熵,那么就是尽可能减小Training Loss。以上函数其实就是关于w和b的函数。
我们假设某惩罚函数只有两个变量w1和w2,这个惩罚函数的值在w1 w2的某些区域内很大,在另一区域却很小。我们的目标是寻找到惩罚函数最小的区域,因而我们将一个机器学习问题变成了一个数学的数值优化问题。
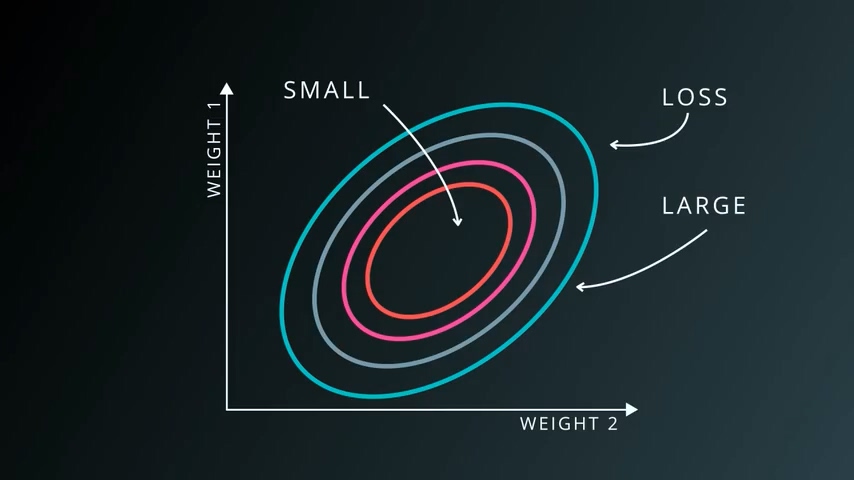
这个优化过程最简单的办法是梯度下降法,我们之前已经了解过。对惩罚函数求导,将每个变量值再加上该偏导函数值,反复进行,知道到达全局最小值。
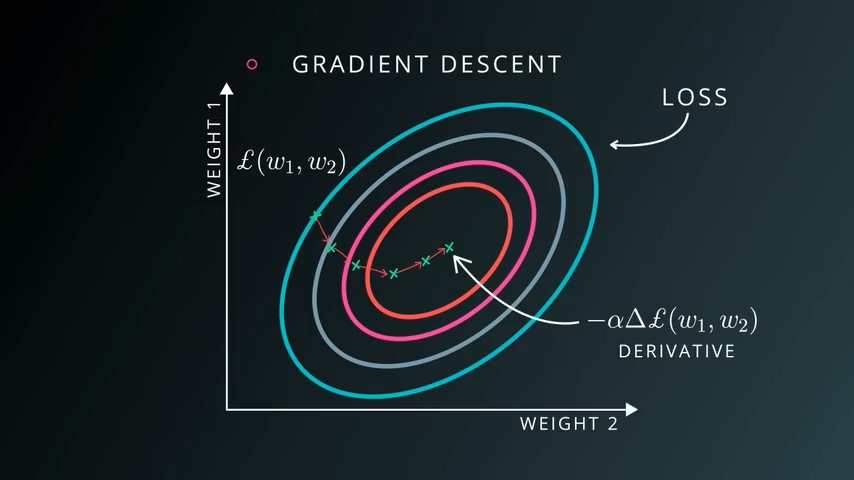
不过需要注意的是以上只是一个二院函数的偏导数求算过程,但对于一个一般问题我们可能会面临几十几百甚至几千个变量,这个计算过程将会变得非常复杂。
发表评论
Want to join the discussion?Feel free to contribute!