
05-01 CNN–直觉与滤波器
卷积神经网络用于识别和分类非常有效,它具有很多人脑的特征,例如我们所说的直觉。我们人类是如何将某个物品归类的呢?一般的识别流程是这样的:
- 把图像区分成很多个小的碎片
- 识别某些固定的特征元素,例如眼睛,鼻子,毛发
- 把这些元素都集合起来归类为某一种物品
这个过程就像人的“直觉”,我们就在神经网络中来实现直觉。
直觉Intuition
举个例子,我们看到如下图片可以很快说出这是一只金毛犬

我们遵循上面的步骤一步步去识别特征点:
– 一个鼻子
– 两只眼睛
– 金色的毛发


从直觉到理论
我们在第一眼直觉的基础上再往下,我们怎么能准确分辨出这是一个鼻子?金毛的鼻子可以看做是一个椭圆形的形状中有两个黑洞,因此我们对狗鼻子进行分类的方法是将其分解成更小的碎片,并寻找可以定义椭圆形的黑洞(鼻孔)和曲线。

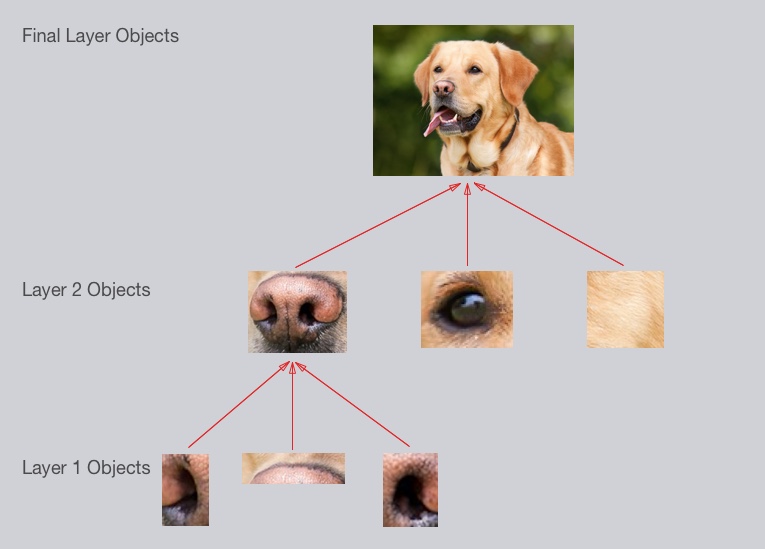
广义上讲这也是卷积神经网络CNN所做的事情,它识别最基础的线条和曲线,然后组合成形状和斑点,再组合成图像中越来越复杂的对象,最后CNN结合这些对象对图像进行分类。在我们这个例子中我们的层次结构分别为:
– 简单的形状,例如椭圆形与黑色的圆形
– 简单形状的组合(复杂物体),例如眼睛,鼻子,皮毛
– 复杂对象的组合(狗)
我们反复强调层次,这就是卷积神经网络的意义。我们并不需要告诉CNN应该去识别眼睛鼻子毛发等特征点,CNN会自己通过前向传播与反向传播学习到这些特征点。
现在我们将去学习更详细的实现。
滤波器Filters
CNN的第一步是将图像分解成小块,小块的长宽定义了一个滤波器,滤波器的尺寸等同于小块的尺寸。
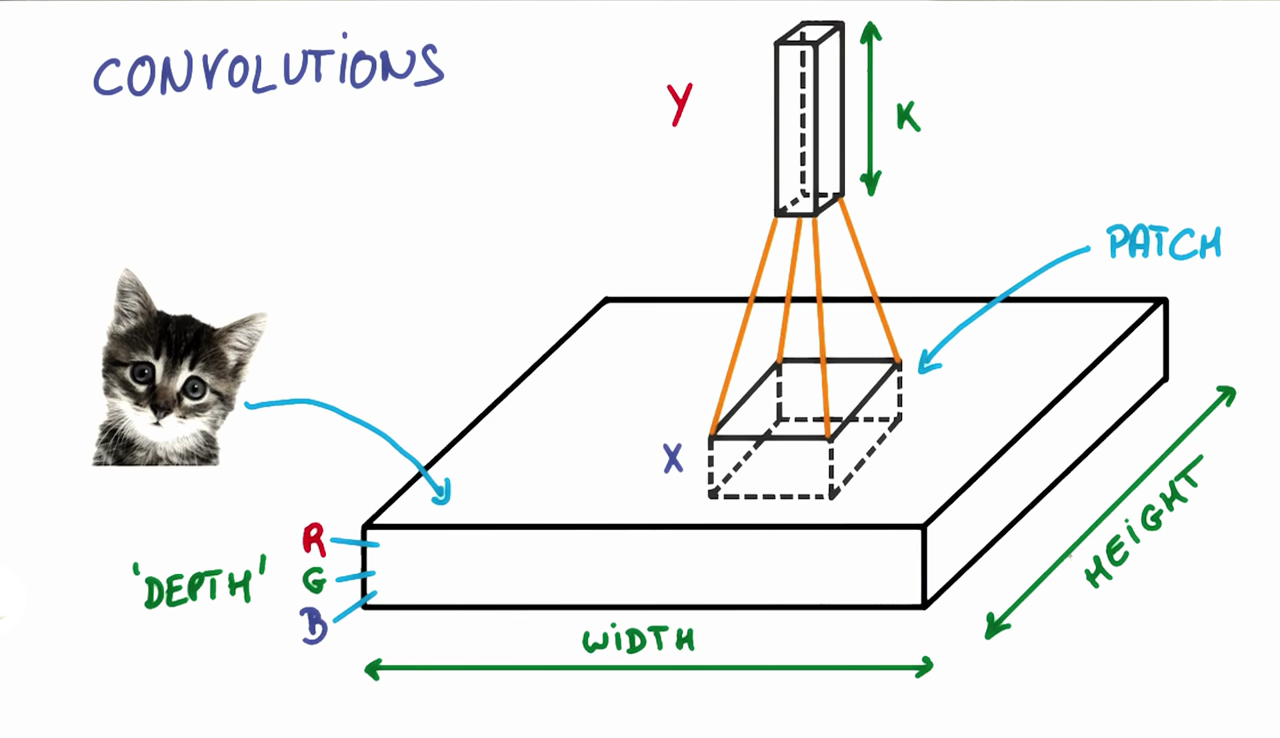
我们向垂直或者水平方向移动这个滤波器,得到图像的不同部分。滤波器移动的次数取决于我们所设定的“步幅”。这个步幅是我们可以调节的参数,步幅设置得比较大则滤波器截取出的小块的数量较少,同时也会带来精度下架的问题。
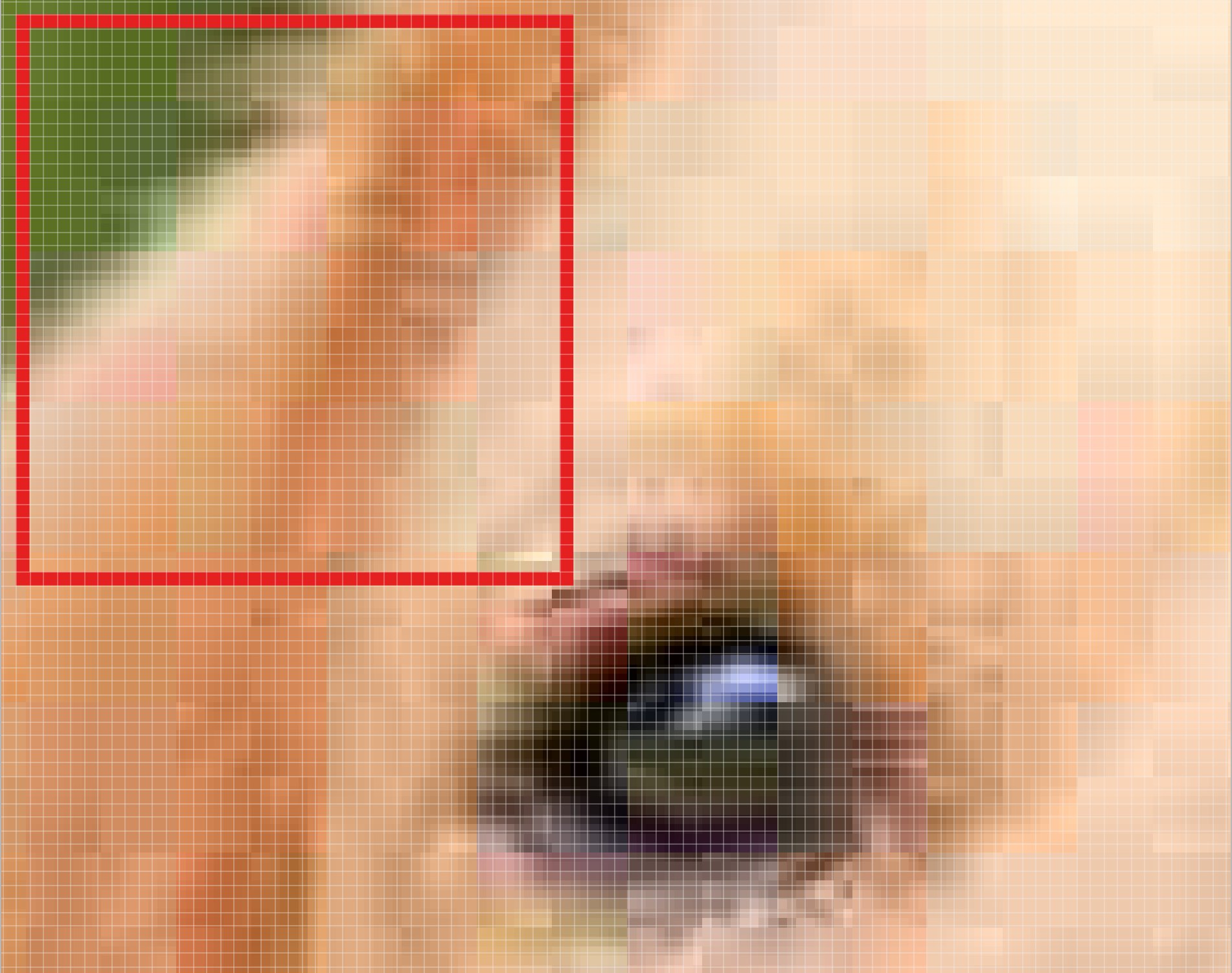
我们向右边移动一个步幅(这里设定的是2像素),这样我们就获得了另一个小块。

这一步最核心的是我们将相邻的像素组合在一起并将他们视为一个整体,这在之前的网络中是没有体现出这个关系的。在没有学习CNN之前我们忽略掉了这个关键问题。我们将所有像素都输入到一个神经网络,并没有利用这些像素点之间的位置关系。图像之所以有意义就是这些像素的相对位置构成了一定含义。
正是由于利用了这样的关系,CNN可以从图片中学习到形状、对象等等
滤波器深度
一个CNN中有不同的滤波器是比较常见的,不同种类的滤波器摘取不同的特征。例如:这个滤波器关注特定的颜色,另一个滤波器关注特定的形状,CNN中滤波器的数量就称为滤波器深度(Filter Depth)
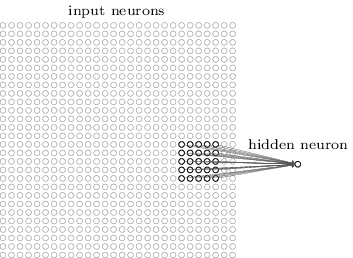
在上图中,每个小块连接了多少神经元呢?这取决于滤波器深度。如果我们设定滤波器深度为k,我们将每个小块内的像素点连接到下一层网络的k个神经元中。这也决定了下一层网络的深度k,如下图所示。
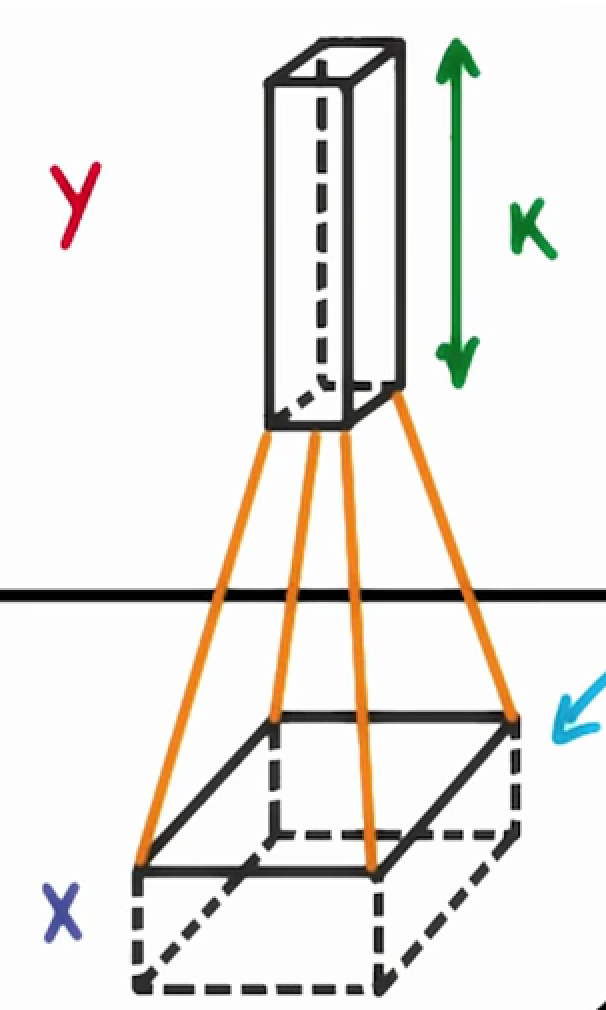
k是我们可以调节的另一个参数,大部分CNN采用同一个初始值。
为什么我们要把一个小块连接到多个神经元呢?一个神经元不行吗?
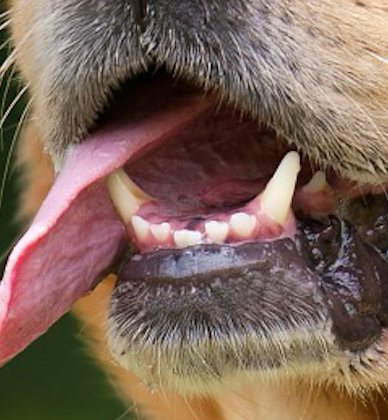
多个神经元是非常有用的,它可以关注多个特性。举个例子,我们选取的一个小块可能有牙齿,金色的胡须,部分红色的舌头。在这个情况下我们希望滤波器深度至少为3个:牙齿,胡须,舌头
一个小块对应多个神经网络可以保证我们的CNN可以抓住很多特点。需要记住的是,CNN去学习那些特征不是我们去设定或者变成的,它是自己学习到这些特征的。
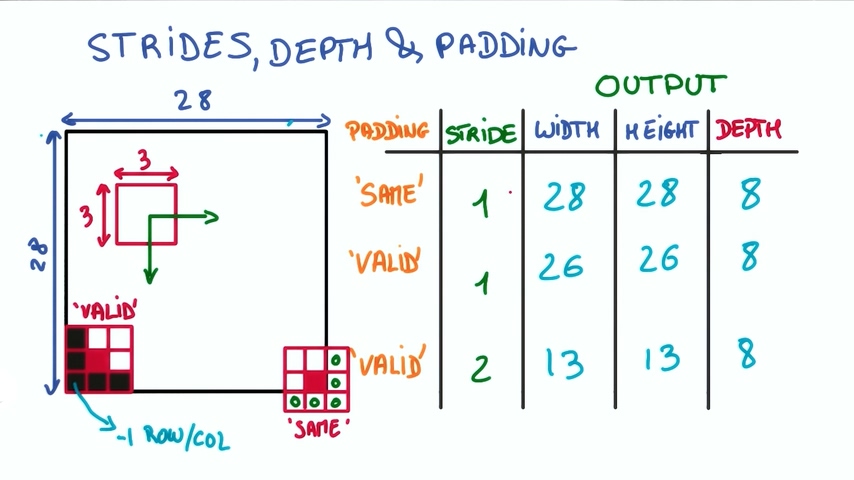
feature map尺寸
假设我们有一张28*28尺寸的图片,在上面进行3*3的卷积操作,滤波器深度是8,那么在执行以下操作时,输出的维度分别是多少呢?
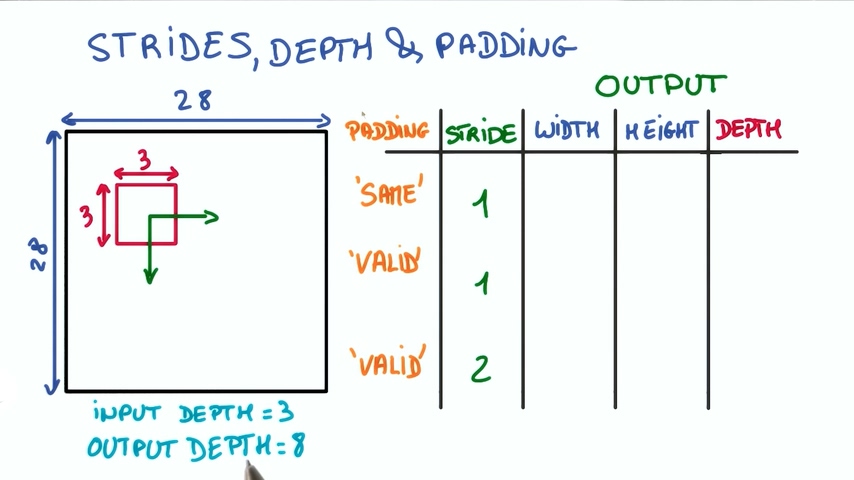
- 相同填充,步幅为1
- 有效填充,步幅为1
- 有效填充,步幅为2
对应的:
1. 如果使用相同填充,则允许小块超出原图像边界并用0填充,因为步幅为1,所以输出的尺寸也应该是28*28
2. 如果使用有效填充,则不允许小块超出原图像边界,那么有效的部分是26*26,又因为步幅为1,所以输出的尺寸是26*26
3. 由于步幅为2,输出尺寸为有效尺寸的1/2,所以输出尺寸为13*13
4. 由于滤波深度为8,所以以上条件下输出的深度都为8
发表评论
Want to join the discussion?Feel free to contribute!